

研究の概要
背景と課題
近年、ビッグデータの収集と蓄積が容易になったことで、あらゆる機関が集めたデータの解析に取り組んでいる。しかし、各機関のデータには、偏りやサンプル数の少なさといった問題がある。一方で、複数の機関のデータを集約するのは、特に医療データにおいては、プライバシー保護の観点から困難である。
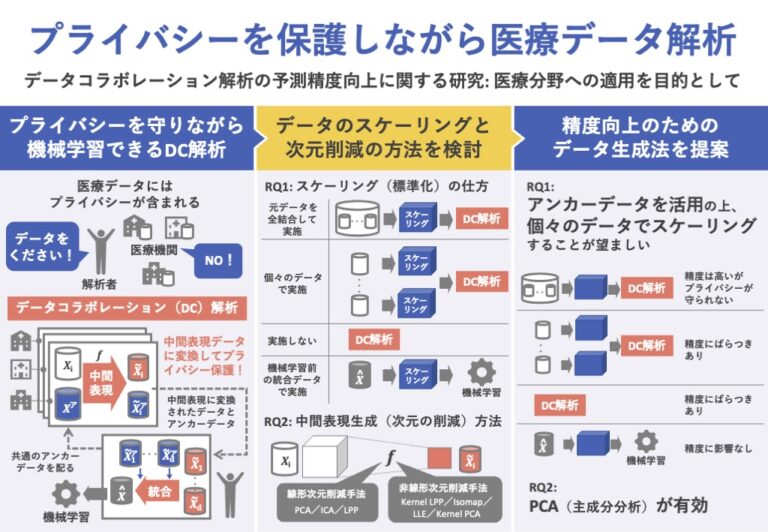
そこで、複数の機関が分散して保持するデータを、プライバシーを保護したまま統合・解析するための手法、協調機械学習に関する研究が盛んに行われている。今倉・櫻井(2020)が提案するデータコラボレーション(DC)解析もその一つである。
DC解析では、各機関は元データを独自の次元削減関数によって中間表現データに変換した上で、解析者に共有する。中間表現データを元データに逆変換することは不可能なため、プライバシーは保護されることになる。
このDC解析の有効性は先行研究によって示されているものの、解析者や参加機関による恣意的な決定が必要な事がらが多く、学習精度向上をもたらす一般的な分析プロセスの枠組みはいまだ確立されていない。
そこで本研究では、医療分野への応用を想定し、実データを含む3種類の医療データを用いて、データ前処理の仕方が、最終的な学習予測精度にどのように影響するのか(RQ1)、中間表現生成方法の違いが、最終的な学習予測精度のどのように影響するのか(RQ2)を検証する。
データ分析
データコラボレーション解析
参加機関数を𝑑とし、𝑖番目の機関が元データ (1 ≤ 𝑖 ≤ 𝑑)をもつとする。ここで、は𝑖番目の機関のデータ数、𝑚はデータの次元である。まず、各機関は、独自の中間表現生成関数(次元削減関数)を用いて次元削減を行い、元データを中間表現に変換する。
中間表現は元データとは分布も次元数も異なるため、そのままでは統合して解析することはできない。そこで、アンカーデータ( )と名付けた、各機関共通の共有可能データを導入する。
そして、各機関それぞれの中間表現生成関数で変換したアンカーデータを用いて射影行列を求め、各機関の統合表現を求める。最終的に、𝑑機関分のデータを結合し、全機関分の統合表現を得る。解析者はこの統合表現を用いて、各種分類問題あるいは予測問題タスクを解く。
一連のDC解析のステップは次の通りである。
- 解析者は、アンカーデータを生成し、全機関に配布する。
- 各機関は、独自の中間表現生成関数を用いて、自身の元データの中間表現、アンカーデータの中間表現を求め、正解ラベル(実際に病気だったかどうか、などの正解情報)とともに解析者に共有する。
- 解析者は、元データ、およびアンカーデータの𝑑機関分の中間表現を用いて、統合表現を得る。統合表現と正解ラベルを用いて機械学習を行う。
使用データ
UCI repositoryより2種類のオープンデータ①慢性腎臓病(CKD)データ、②乳がん(BC)データ、実データとして③特定健診の計3種類のデータを用いる。そして、参加機関数を4とし、各データを分割することで、擬似的に複数の機関がコラボレーションする状況を作りだす。
データの分割方法として、全ての機関においてデータ分布が同一となる「IID(独立同一分布)分割」と、分布にばらつきがある「Non-IID(非独立同一分布)分割」の場合で分析を行い、結果の頑健性を確かめる。
CKDデータは慢性腎臓病か否かの2クラス分類、BCデータは悪性腫瘍(乳がん)か否かの2クラス分類を行う。特定健診データは7府県の2008~2013年のデータから4県分を選択、2008年と比較し、翌年から3年間の間に腎臓機能の指標eGFR値が30%低下するか否かの2クラス予測を行う。
CKD・BCデータでは機械学習モデルとしてk近傍法を採用する。特定健診データでは、ロジスティック回帰モデルを採用する。評価指標として、正解率、適合率、F1値を算出する。特定健診データでは、閾値を設定せずに算出可能なAUCも求める。
データ前処理の仕方の影響の検証(RQ1)
データの平均と標準偏差に基づく標準化をデータ前処理(スケーリング)として採用し、データ前処理の仕方の影響の検証のために、以下の4パターンを比較する。
- All scaling 各機関の元データを全結合させた状態でスケーリングを施す場合
- Edge scaling 各機関が個々でスケーリングを施す場合
- No scaling 一度もスケーリングを施さない場合
- g_scaling 統合表現を構築後、機械学習モデルを用いて学習させる前にスケーリングを施す場合
中間表現生成方法の影響の検証(RQ2)
中間表現生成方法の影響を検証するために、RQ1の分析結果に基づく最適なスケーリング処理を用いて、データがIID分割の場合のDC解析を行う。中間表現作成方法として、主成分分析(PCA)、独立成分分析(ICA)、LPPの3種類の線形次元削減手法と、Kernel LPP、Isomap、Locally Linear Embedding(LLE)、Kernel PCAの4種類の非線形次元削減手法を比較検証する。
評価・実証
データ前処理の仕方の影響(RQ1)
まず、g_scalingの有無が精度向上に寄与する傾向は見られなかった。これを踏まえ、以降ではg_scalingを行わない場合に着目し、議論する。
概して、元データ全体にスケーリングを施した後に次元削減を行うAll scalingの予測精度が最も優れていた。また、最も精度が悪くなるのは次元圧縮前にスケーリングを行わないNo scalingであった。
例外はBCデータのNon-IID分割で、元データにスケーリングを施さないNo scalingが最も良い精度となった。また、Edge scalingはAll scalingと比較し約30%の大幅な精度低下が確認された。
そこでBCデータの分布を確認したところ、BCデータのEdge scalingでは、統合表現の値はほぼ0に近く、データにばらつきがほとんど見られなかった。
ゆえに、スケーリング処理方法の違いは、スケーリング後および中間表現生成という二段階の射影変換後におけるアンカーデータと元データの分布のばらつきに違いをもたらし、それが統合表現の推定誤差につながるということが示唆された。
中間表現生成方法の影響(RQ2)
CKD・BCデータにおいては線形次元削減手法であるPCAが最も精度が優れ、非線形次元削減手法であるKernel PCA、Kernel LPPの順に精度が悪かった。特定健診データでは、Kernel LPPではなくIsomap、LLEにおいて予測精度の下落が見受けられた。
一方でBCデータでは、非線形次元削減手法であるIsomapとLLEでもLPPと同等の精度を得ることが出来ている。IsomapやLLEはデータの構造をできるだけ保持するように別空間への射影を学習する手法である。
成果と提案
統合表現に対するスケーリング処理が、最終的な学習精度に与える影響は小さいことがわかった。一方で、全機関のデータに合わせたスケーリングを施すか、各機関のデータ範囲に合わせたスケーリングを施すかによって、最終的な機械学習精度が大きく異なることが明らかとなった。
All Scalingを用いることで最終的な機械学習精度の向上は期待できるが、元データの共有が必要となってしまう。しかしながら、アンカーデータを活用することで、データの共有なしにAll Scaling同様のスケーリング効果を得ることも可能であると考える。
次元削減手法については、PCAやICAなどの線形次元圧縮方法や、元データの近傍を保持するような次元圧縮方法を用いることで、最終的に統合表現の機械学習精度向上につながることが示唆された。