

研究の概要
背景と課題
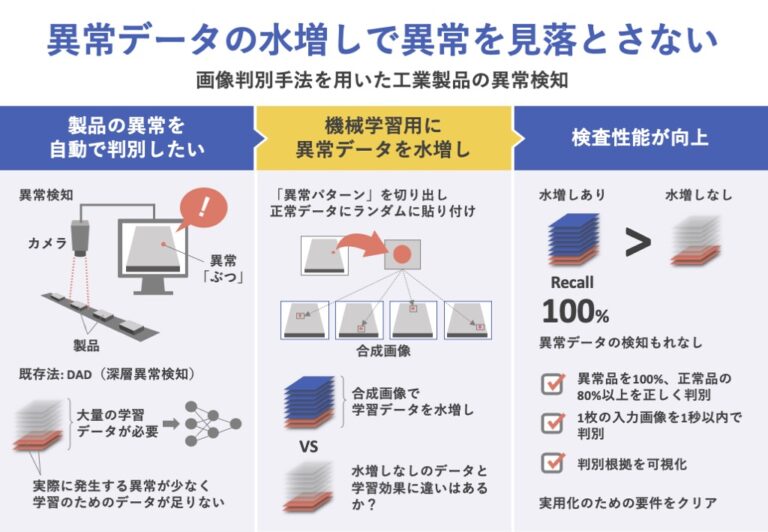
異常検知(製造された工業製品が期待される品質とは異なるときに、それを異常品として取り除く作業)は工業製品の製造現場で重要な工程である。しかしながら、コストや能力差、人員不足の問題から、近年ではその自動化に対する需要が高まっている。
本研究は、車載部品メーカーの株式会社松田電機工業所(M社)との共同研究である。なお、ここで扱う分野は製品検査のみに限定し、画像データのみをデータとする。
異常検知には、ディープニューラルネットワークに基づく手法、深層異常検知(DAD)が主に利用されている。しかし、学習のために正常と異常のラベルが付与されたデータを大量に用意する必要があるが、一般的に異常の発生率は低いため、データ収集は困難となる。
この問題への対処として、画像認識タスクにおけるデータ拡張(DA)が有名である。DAは、画像に対して水平方向の反転や移動などを行い、データ数を水増しする技術である。
本研究では、高性能な異常検知の判別モデルを作成するために、教師ありDADの異常データ不足の問題を克服することに焦点を当て、合成画像による画像水増しで異常データの補完を行う。そして、実際の異常画像を使って学習したモデルと合成画像を使って学習したモデルの精度比較を行い、有効性を検証する。
データセットとしてM社の製造現場で撮影した車載部品の画像データを用いる。本研究は、M社でのヒアリングにより判明した次の3点、異常品を全て正しく&正常品の80%以上を正しく判別すること、1枚の入力画像を1秒以内で判別すること、作業員が確認できるように判別根拠を可視化すること、を要件とする。
提案手法
異常画像から異常の領域のみを切り取った画像(異常パターン)を正常画像に張り付けて、異常の合成画像を生成する。その際、異常パターンを張り付ける場所と異常パターンの形状・色をランダム化する。
ただし、異常パターンを画像内の任意の場所に貼り付けると、背景に異常があり物体は正常のままとなる可能性がある。そこで、異常パターンを張り付ける場所は画像内で異常が発生しうる領域のみに限定する。そのために、事前にデータ成形として、画像内の物体と背景の領域を区別しておく。
扱うデータセットは3種類の車載部品の画像データセットである(図1)。表面を注視すると一部に黒い点が存在している。これは「ぶつ」と呼ばれる異常である。データセットの各画像のサイズは全て1024×1024ピクセルのRGB画像である。
データセットの内訳は、部品Aが正常108、異常7、部品Bが正常108、異常6、部品Cが正常146、異常8である。これらの特徴は、異常箇所が小さい(画像は1024×1024ピクセルに対して「ぶつ」は10×10ピクセル程度)こと、全ての画像の照明と角度は統一されているが背景は統一されていないことである。

提案手法のフロー
提案手法の流れは次のとおりである。(1)学習用異常画像から異常パターンを抽出する。(2)空の正常クラスに学習用正常画像を全て格納する。(3)正常クラスの全ての画像を複製し空の異常クラスに格納する。
そして、(4)学習段階において異常クラスの画像を読み込む際に、画像内に(1)の異常パターンをランダムな場所(ただし物体の領域に限定)に張り付ける。張り付けの際には、パターンにサイズ変更とDAを適用する。
(5)正常クラスと異常クラスの画像に対してピクセルのズレに対して頑健性を持たせるためのDAなどを適用し、最終的な学習用の入力画像とする。
評価・実証
合成画像を使用する学習の有効性を検証するために、合成画像を使用しない学習との比較実験を行う。合成画像を使用する学習では、学習用異常画像1枚を異常パターン抽出のために使い、実際に学習に用いる異常画像には学習用正常画像を複製したものを使う。
CNNのアーキテクチャには18層のResNetを採用する。ネットワークの重みの初期値はImageNetで1000クラス分類学習を行ったものを使用し、出力層は1000クラス分類用から2クラス分類用に変更する。
合成画像作成後、次元圧縮のために画像を1024×1024ピクセルから512×512ピクセルに縮小する。また、ピクセルのズレに対して頑健性を持たせるために正常クラスと異常クラスの共通にRandom Crop(512×512ピクセルから500×500ピクセルをランダムに切り出す)を行い、最終的な入力画像とする。
異常検知では、異常を正常と間違えないことが理想であるため、異常クラスのRecall(再現率: 異常と判別し正解だった件数が実際の異常件数の何%か)が評価指標として重要視される。
判別根拠を示すために、Gradient-weighted Class Activation Mapping(Grad-CAM)を採用する。これはそのクラスの出力値に与える画像の各ピクセルの重要度をヒートマップとして出力するものである。
実験結果
判別根拠をヒートマップで示した(図2)。図中のdataは評価用データ(赤い正方形は正解の異常箇所)であり、result1(合成画像なし)、result2(合成画像あり)はGrad-CAMを適用した結果である。画像内の赤い部分ほど判別根拠として重要な箇所であることを示している。右上の丸は判別に失敗したことを表す。
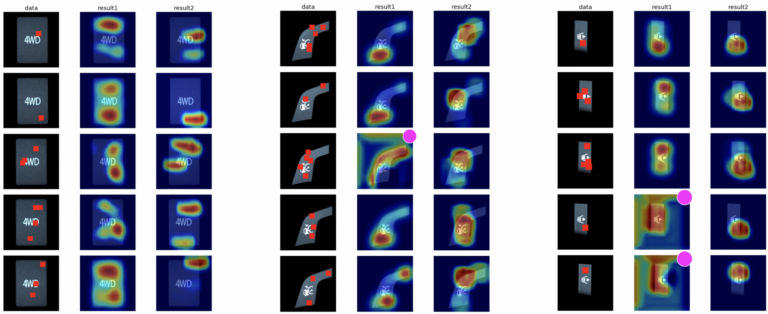
合成画像ありのモデルは、全ての部品においてRecall 100%を達成し、正常クラス内でも80%以上の部品を正しく判別した。一方で、合成画像なしのモデルは、部品AはRecall 100%、部品Bと部品CはRecall 100%未満だった。また、判別根拠の可視化の結果を見ると、合成画像ありのモデルの方が全体的に異常箇所を判別根拠としていることが分かる。
合成画像ありの方が良い結果となったのは、異常パターンを様々な場所にランダムに貼り付けた事が要因で、異常箇所を判別根拠とするように学習が行なわれたためだと考える。また、正常画像50枚と異常画像1枚で学習を実現できた点から、データ収集のコストが低い実用的な手法であるといえる。
判別時間として、1枚の画像に対して、元画像を入力してからデータ成形とモデルへの入力を経て判別結果を出すまでの時間を測定し、1枚の画像に対して100回行った平均と標準偏差を求めた。その結果、GPUなしでも平均0.365秒であり、目標の1秒未満を達成できた。
成果と提案
本研究では、高性能な異常検知の判別モデルを作成することを意図し、教師ありDADの異常データ不足の問題を克服するために、合成画像による画像水増しで異常データの補完を試みた。
その結果、全ての部品において、当初目標としていた3要件を満たすことが出来た。すなわち、提案手法は、良い精度かつ短い判別時間、そして判別根拠の可視化が可能であるため、異常検知システムとして実用的であると結論づける。
この記事は、下記の論文を要約したものです
矢口 拓哉(2020)画像判別手法を用いた工業製品の異常検知、2019年度 筑波大学 大学院 博士課程 システム情報工学研究科 修士論文。