

取り組みの概要
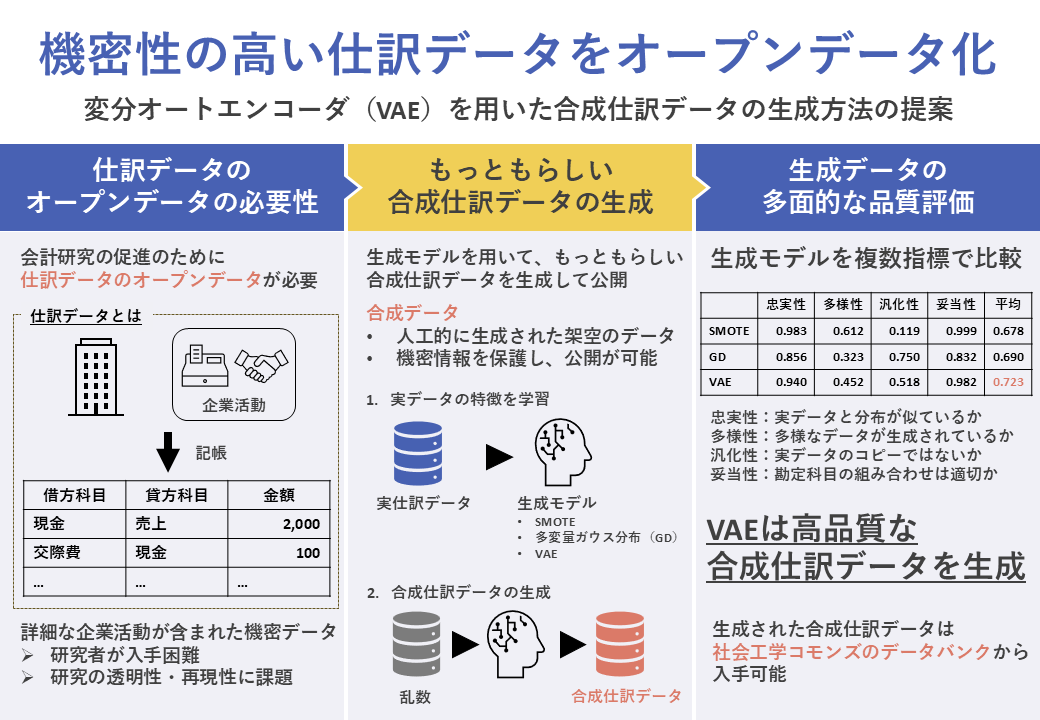
背景と課題
仕訳データの重要性
- 仕訳データは、経営組織の実態に関する詳細でタイムリーな情報を提供する
- グラフ理論や機械学習を用いた可視化・分析により、経営分析や監査での活用が進む
仕訳データの機密性
- 仕訳データは詳細な企業活動を含む機密データであり、簡単に外部へ共有できないため入手が困難
- データを取得しても外部公開ができない場合が多く、研究の再現性や透明性に課題がある
合成データ
- 実データをもとに、人工的に生成された架空のデータ
- 機密情報を保護しながら、データの共有や公開が可能
本研究は、生成モデルを用いてもっともらしい合成仕訳データを生成し、オープンデータとして公開することで、会計研究の促進・オープンサイエンス化に貢献する。
使用するデータ
共同研究先である税理士法人日本経営から提供された、6つの医療法人の仕訳データを使用する。
- 各医療法人は異なる部門・会計体制を持つため、モデル学習・生成は医療法人ごとに個別に実施
- 2016~2021年までのデータを使用してモデルを学習
- 1年間に約1,500~4,000の仕訳が含まれ、学習データは約8,000~25,000
- 借方勘定科目、貸方勘定科目、金額の3つの特徴量を使用
| 法人 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 合計 |
| A | 1,141 | 1,503 | 1,455 | 1,499 | 1,387 | 1,406 | 8,391 |
| B | 880 | 3,893 | 4,450 | 4,480 | 4,398 | 4,739 | 22,840 |
| C | 680 | 1,975 | 2,088 | 2,198 | 2,106 | 2,060 | 11,107 |
| D | 2,670 | 3,020 | 2,935 | 2,987 | 2,782 | 2,537 | 16,991 |
| E | 1,029 | 1,661 | 1,541 | 1,469 | 1,405 | 1,372 | 8,477 |
| F | 775 | 3,020 | 2,841 | 3,009 | 2,718 | 2,503 | 14,866 |
評価手法
合成データの評価で推奨されている3つの観点[1]に仕訳データ特有の観点を1つ追加し、生成した合成仕訳データの品質を以下の4つの観点で評価する。
- 忠実性:合成データと実データの分布が類似しているか
- 多様性:合成データが実データの多様性をどれだけカバーしているか
- 汎化性:合成データが実データの単なるコピーではないか
- 妥当性:合成データの借方科目・貸方科目の組み合わせが会計的に妥当か
各指標は1に近いほど高品質であることを示す。
提案手法
使用する生成モデル
先行研究[2]において、合成仕訳データの生成の有効性が示唆されている変分オートエンコーダと2つの手法を比較する。
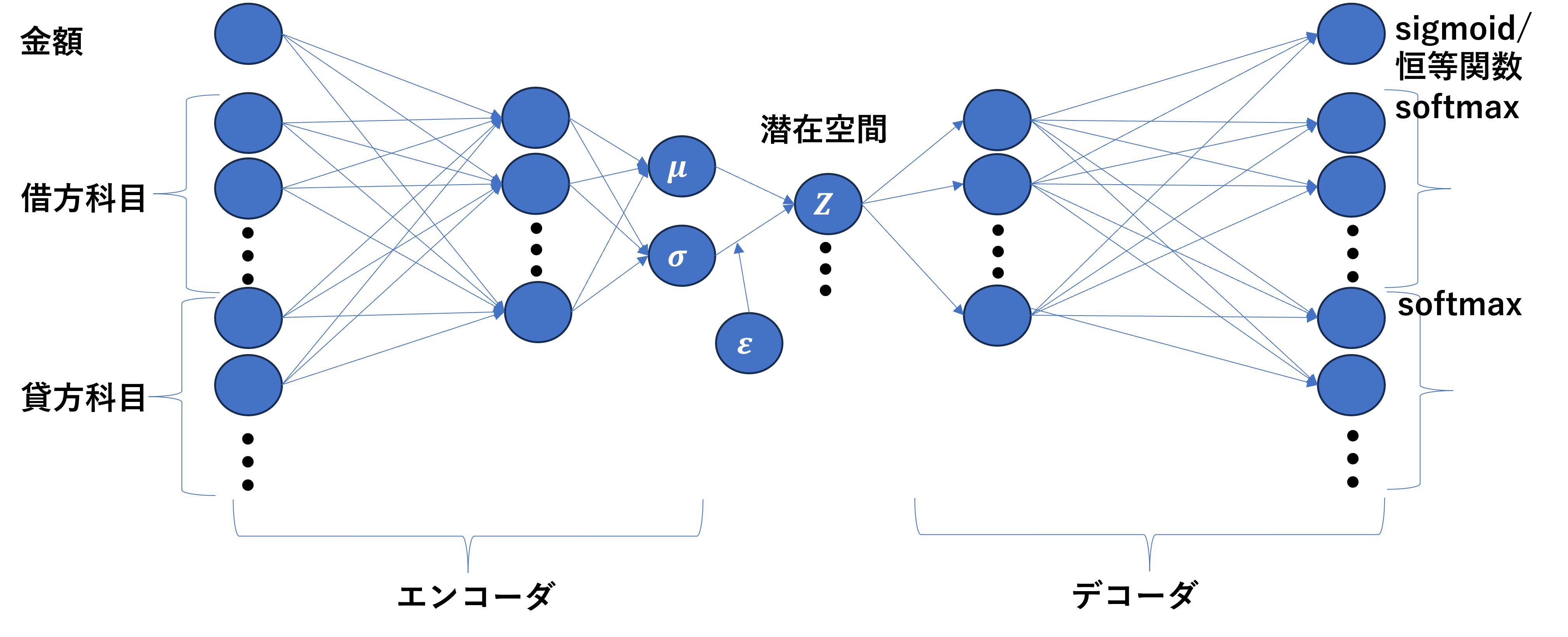
- 変分オートエンコーダ(VAE)[3]:データの潜在空間を推定し、その分布から新しいデータを生成する深層学習の手法
- SMOTE-NC[4]:質的データに対応可能なオーバーサンプリング手法
- 多変量ガウス分布(GD):変分ベイズ法で推定された多変量ガウス分布からサンプリング(VAEの潜在空間にGDを仮定しているため、比較のベースラインとなる)
生成方法
- 前処理
- 勘定科目:借方・貸方を別々にOne-hotエンコーディング
- 金額:複数のスケーリング方法を比較検討
- 正規化:データの最小値が0、最大値が1になるように線形変換
- 対数変換:外れ値の影響を軽減
- 対数変換+正規化:対数変換した後に0–1の範囲にスケーリング
- Box-Cox変換:対数変換の一般化で、パラメータにより正規分布に近づくよう変換
- 分位数変換:金額を1000分位に分け、0–1にマッピング
- 学習
- VAEは30次元の単一の隠れ層をもつ
- 潜在空間にはガウス分布を仮定し、次元数は9に設定
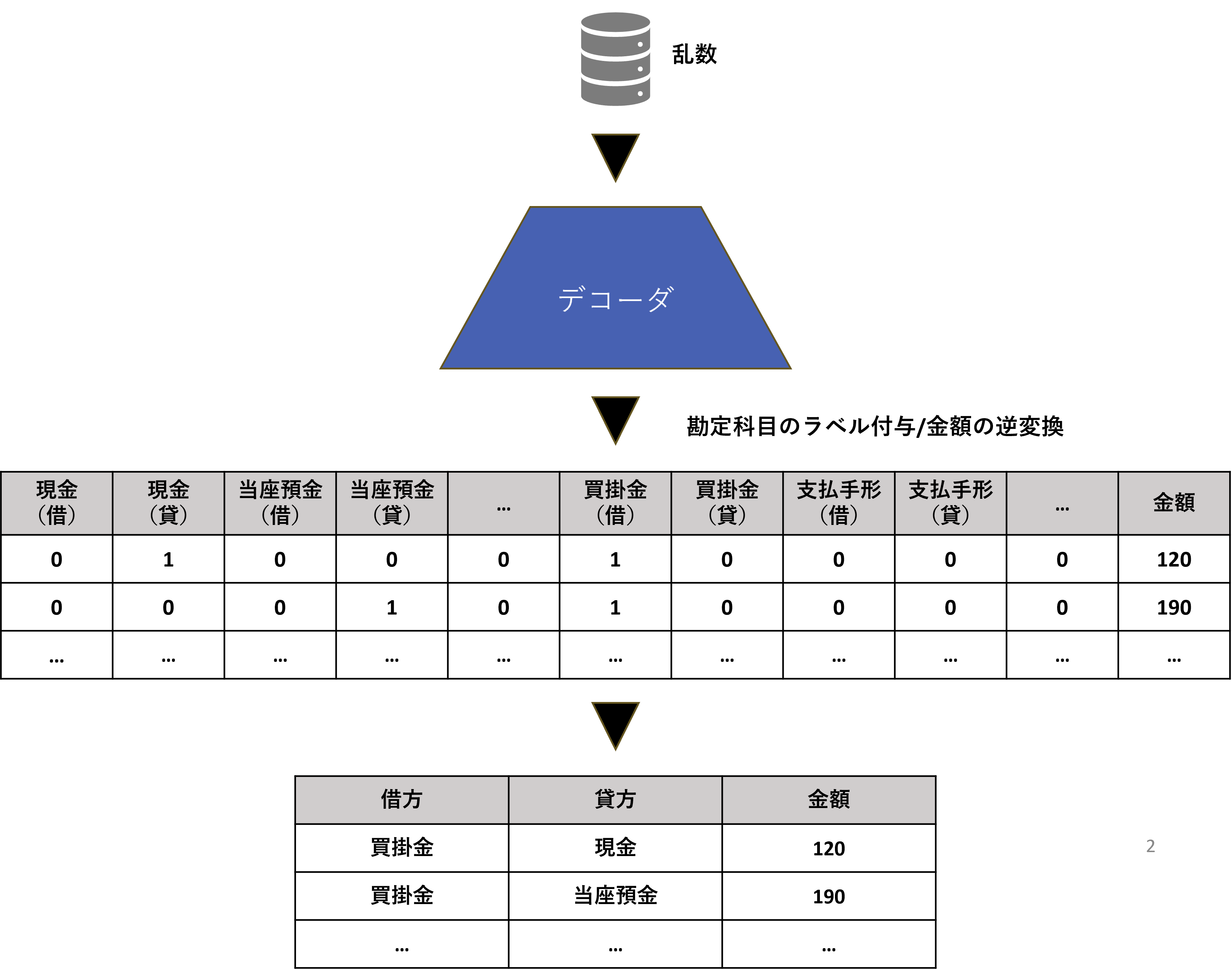
- 合成仕訳データの生成
- 学習が完了したVAEのデコーダに乱数を入力する
- デコーダから出力された高次元の数値データを合成仕訳データに変換
- 勘定科目のラベルを割り当て
- 金額を元のスケールに逆変換
成果と提案
- 複式簿記の基本構造を保持する合成仕訳データを生成する方法論を提案した
- VAE+対数変換が、全体として最も高品質な合成仕訳データを生成した
- VAEはSMOTE-NC・GDと比較して、総合評価(4指標の平均)で最良のスコアを示した
| スケーリング | 忠実性 | 多様性 | 汎化性 | 妥当性 | 総合評価 |
| 正規化 | 0.983 (1) | 0.612 (2) | 0.119 (2) | 0.999 (5) | 0.678 (1) |
| 対数変換 | 0.978 (3) | 0.612 (2) | 0.115 (5) | 1.000 (1) | 0.676 (5) |
| 対数変換+正規化 | 0.978 (3) | 0.612 (2) | 0.118 (4) | 1.000 (1) | 0.677 (4) |
| Box-Cox変換 | 0.981 (2) | 0.613 (2) | 0.119 (2) | 1.000 (1) | 0.678 (1) |
| 分位数変換 | 0.978 (3) | 0.523 (2) | 0.212 (1) | 1.000 (1) | 0.678 (1) |
| スケーリング | 忠実性 | 多様性 | 汎化性 | 妥当性 | 総合評価 |
| 正規化 | 0.745 (5) | 0.109 (5) | 0.923 (1) | 0.831 (3) | 0.652 (5) |
| 対数変換 | 0.852 (3) | 0.321 (3) | 0.753 (2) | 0.832 (1) | 0.689 (2) |
| 対数変換+正規化 | 0.852 (3) | 0.321 (3) | 0.753 (2) | 0.831 (3) | 0.689 (2) |
| Box-Cox変換 | 0.856 (1) | 0.322 (2) | 0.750 (4) | 0.832 (1) | 0.690 (1) |
| 分位数変換 | 0.855 (2) | 0.324 (1) | 0.711 (5) | 0.831 (3) | 0.680 (4) |
| スケーリング | 忠実性 | 多様性 | 汎化性 | 妥当性 | 総合評価 |
| 正規化 | 0.846 (5) | 0.233 (5) | 0.762 (1) | 0.993 (1) | 0.708 (2) |
| 対数変換 | 0.940 (1) | 0.452 (1) | 0.518 (3) | 0.982 (5) | 0.723 (1) |
| 対数変換+正規化 | 0.891 (4) | 0.301 (3) | 0.532 (2) | 0.991 (3) | 0.679 (4) |
| Box-Cox変換 | 0.933 (2) | 0.399 (2) | 0.515 (4) | 0.986 (4) | 0.708 (2) |
| 分位数変換 | 0.893 (3) | 0.294 (4) | 0.483 (5) | 0.992 (2) | 0.665 (5) |
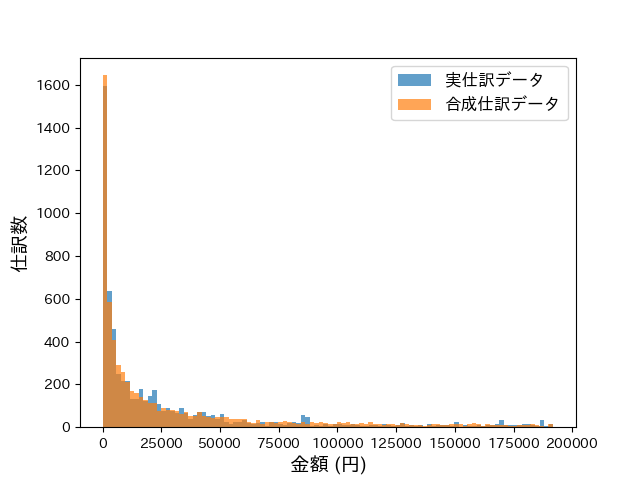
本研究によって生成された合成仕訳データは、社会工学コモンズのデータバンクに公開され、オープンデータとなっている。会計研究や会計教育に本研究の合成仕訳データが利用されることを期待している。
後記
本研究を通じて、新しいことに挑戦する難しさと楽しさを実感することができました。本研究は、合成仕訳データの生成手法を提案する初めての試みであり、「どのような手法で生成するか」「どのように合成仕訳データの品質を評価するか」といった点に困難がありました。このような課題に対して、広い視野で先行研究を調べること、アイデアを小さく早いサイクルで試すことを意識して取り組みました。その結果、先輩方や先生、共同研究先の皆様のサポートのおかげで、論文の発表および合成仕訳データの公開に至ることができたことを大変嬉しく思っています。今後は、使用データの多様化や生成手法のさらなる洗練を進め、よりよい合成仕訳データの生成・公開を目指していきたいです。
税理士法人日本経営には、本研究において大変貴重な仕訳データをご提供いただき、誠にありがとうございました。あわせて、本研究に関するご助言ならびに合成仕訳データの公開に際しての多大なるご協力に、心より感謝申し上げます。
本研究の詳細についてご興味をお持ちの方は、以下の論文をご覧いただけますと幸いです。
Motai, R., Mashiko, S., Kawamata, Y., Shin, R., & Okada, Y. (2025). Generating Synthetic Journal‐Entry Data Using Variational Autoencoder. Intelligent Systems in Accounting, Finance and Management: International Journal, 32(1), e70005. https://doi.org/10.1002/isaf.70005
本研究は JSPS 科研費 23K22166 の助成を受けたものである。
参考文献
[1] Alaa, A., B. Van Breugel, E. S. Saveliev, and M. van der Schaar. 2022.“How Faithful Is Your Synthetic Data? Sample-Level Metrics for Evaluating and Auditing Generative Models.” In Proceedings of the 39thInternational Conference on Machine Learning, 290–306. ML Research Press. https://proceedings.mlr.press/v162/alaa22a.html
[2] Zupan, M., V. Budimir, and S. Letinic. 2020. “Journal Entry Anomaly Detection Model.” Intelligent Systems in Accounting, Finance and Management 27: 197–209. https://doi.org/10.1002/isaf.1485
[3] Kingma, D. P., and M. Welling. 2013. “Auto-Encoding Variational Bayes.” arXiv: 1–14. https://doi.org/10.48550/arXiv.1312.6114
[4] Chawla, N. V., K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer. 2002.“SMOTE: Synthetic Minority Over- Sampling Technique.” Journal of Artificial Intelligence Research 16: 321–357. https://doi.org/10.1613/jair.953