

研究の概要
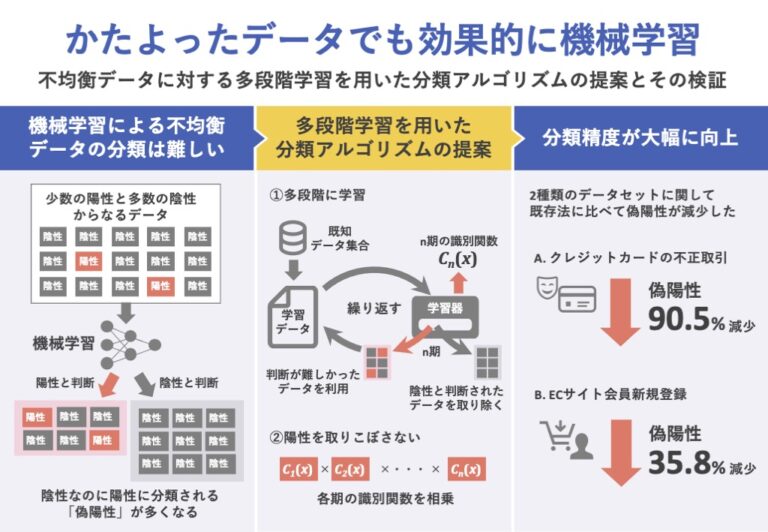
背景と課題
人工知能の一種である機械学習を用いて、あるデータが陽性と陰性のどちらに属するかを求める2クラス分類は、医用画像診断やクレジットカードの不正利用予測など、さまざまな分野で応用されている。
機械学習を用いた分類では、あらかじめ陽性か陰性かが分かっている多数の学習データを用いて、学習させるプロセスが必要となる。しかし、多くの応用例では、対象データが少数の陽性と多数の陰性から不均衡に構成されるため、そのようなデータを用いて学習することによる分類精度の低下が問題となっている。
ところで、学習データの陽性と陰性の比率が1:1になるようにサンプリング(抽出)する手法をサンプリング学習と呼ぶ。その中でも、少数の陽性と同数程度になるように、多数の陰性からサンプリングを行う手法をアンダーサンプリングと呼ぶ。
一方、複数の弱学習器を統合することによって分類精度を向上させる方法をアンサンブル学習と呼ぶ。中でもバギングは、データを分割し、それぞれを学習させた弱学習器を統合する手法である。弱学習器間で異なるデータ集合を用いているため、予測結果のばらつきが少ないことや、学習を並行して行えるという特徴がある。
これまで、不均衡データに対する2クラス分類アルゴリズムとして、アンダーサンプリングとバギングを組み合わせたハイブリッドモデルと呼ばれる手法が提案されてきた。
本研究では、不均衡データの不均衡性の解消による分類精度の向上を目的とし、分類が難しいと判断されたデータに対して多段階に学習を繰り返し、構築された複数のモデルを統合することで陽性を取りこぼさずに偽陽性の減少を図る新しいアルゴリズムを提案する。
評価手法
本研究では提案手法の分類精度を確認するために、二つのデータセットA、Bを用いて実験を行う。
データセットAは、クレジットカード利用履歴2日分である。これを用いて、ある利用履歴が不正取引(陽性)か正常取引(陰性)かの分類を行う。
データセットBは、ある年5~7月におけるECサイトのアクセスログである。これを用いて、同年8月の各セッションにおいてECサイトの会員新規登録が行われる(陽性)か、行われない(陰性)かの分類を行う。
なお、陽性であるデータに対して陽性と予測することを真陽性、陰性と予測することを偽陰性といい、陰性であるデータに対して陽性と予測することを偽陽性、陰性と予測することを真陰性という。
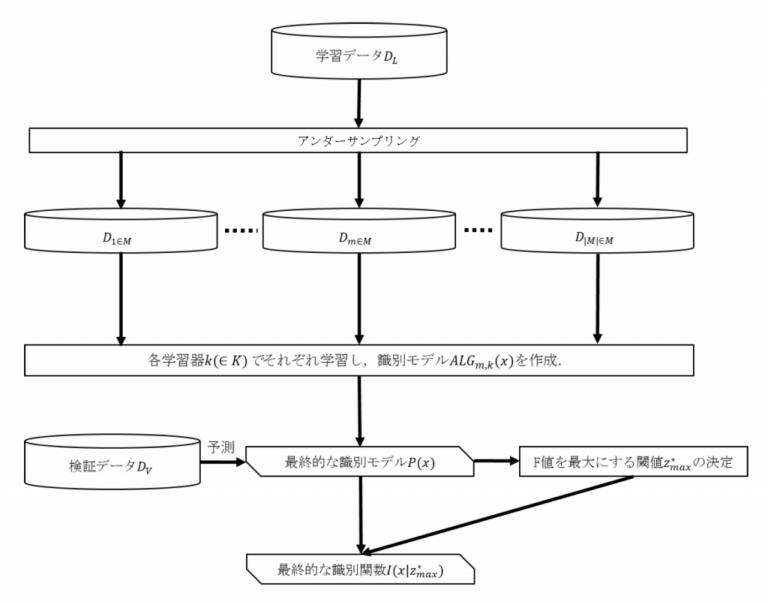
ベースラインモデルの定義
クラス1(陽性)とクラス0(陰性)に分類されている既知のデータxの集合Dがある。Dを学習データ集合DLと検証データ集合DVに分割する。使用する学習器集合をK、学習データ集合DLからアンダーサンプリングによって選ばれたデータ集合の族をMとする。
クラス1かクラス0のどちらかが付与されたデータxに対して、クラス1である確率値p ( x) ∈ [0, 1]を返す確率モデルを識別モデル、識別モデルの出力に対して閾値z ∈ [0, 1]で分類する関数を識別関数と定義する。
ベースラインモデルでは、はじめに、学習データ集合DLから選ばれた各データ集合Dm ∈ Mに対して、各学習器k (∈ K)を用いて学習を行い、識別モデルALGm,k(x)を作成する。この平均を出力するP(x)を最終的な識別モデルとする。
この識別モデルP(x)を用いて、検証データ集合DVに対して閾値z ∈ [0, 1]で分類したときにF値(適合率と再現率の調和平均)を最大にするz*maxを閾値とした識別関数をI (x | z*max)とする(図1)。
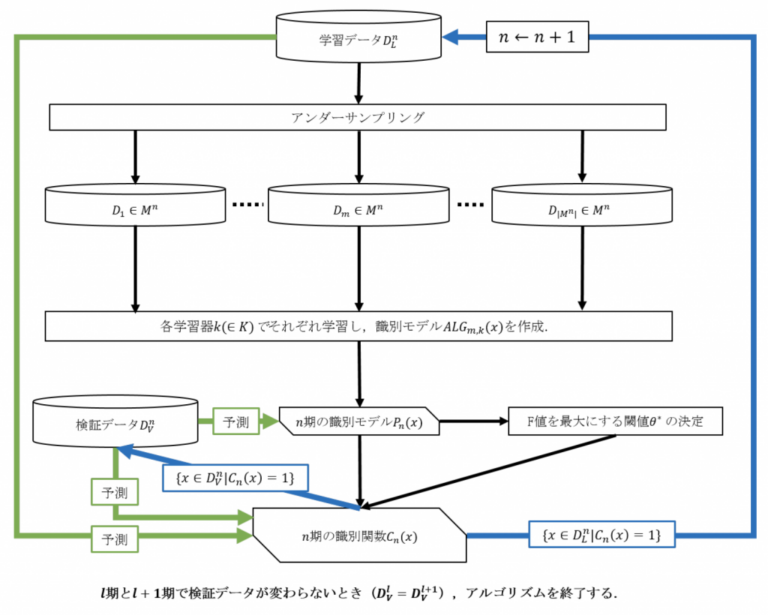
提案手法
提案手法では、学習の過程でモデルから陰性と判断されたデータを段階的に取り除いていくことによって、学習データの不均衡性の解消と評価データの偽陽性の減少を実現する。学習を繰り返す期ごとに識別モデルと識別関数を作成し、前の期で分類が難しいと判断されたデータを用いて次の期の識別モデルを作成する。
n期目で用いる学習データ集合をDnL、検証データ集合をDnVとする。1期目はD1L = DL、D1V = DVとする。使用する学習器集合をK、学習データ集合DnLからアンダーサンプリングによって選ばれたn (= 1, 2, …)期におけるデータ集合の族をMnとする。
n期目では、はじめに、学習データ集合DnLから選ばれた各データ集合Dm ∈ Mnに対して、各学習器k (∈ K)を用いて学習を行い、識別モデルALGm,k(x)を作成する。この平均を出力するPn(x)をn期における識別モデルとする。
この識別モデルPn(x)を用いて、検証データ集合DnVを閾値θ∈ [0, 1]で分類したときの適合率と再現率をPre(x|θ)、Rec(x|θ)で表す。ここで、θ*= argmax0≤θ≤1(Pre(x|θ) | Rec(x|θ) = 1)を求め、それを閾値としたn期の識別関数をCn(x)とする。
次に、n + 1期の学習データ集合をDn+1L = {x ∈ DnL | Cn(x) = 1}、検証データ集合をDn+1v = {x ∈ DnV | Cn(x) = 1}と更新して、次期を同様に繰り返す。すなわち、今期で用いたデータ集合から陰性と判断されたものを取り除き、次期のデータ集合とする。
l期とl + 1期で検証データが変わらないとき(Dlv = Dl+1v)、Pl(x)を用いてDlvに対して閾値zmax∈ [0, 1]で分類したときにF値を最大にするz*maxを閾値とした識別関数I (x | z*max)を作成し、アルゴリズムを終了する。最終的な識別関数はI (x | z*max) ∏ln=1Cn(x)となる(図2)。
提案手法では、各期で生成した陽性を取りこぼさないように分類する識別関数Cn(x)を相乗した∏ln=1Cn(x)によって、明らかな陰性に対して陽性と予測することを防ぐ。これによって、偽陽性の減少を図る。
成果と提案
提案手法の有効性を評価するために、データセットA、データセットBのそれぞれに対して、ベースラインモデル(既存手法)と提案手法とを適用し、結果を比較した。
データセットAに適応した結果、いずれの評価指標においても既存手法より精度が向上していた。偽陽性は既存手法の9.5%と大幅に減少した(表1-左)。
データセットBに適応した結果、いずれの評価指標においても既存手法より精度が向上していた。偽陽性は既存手法の64.2%と大幅に減少した。一方で、偽陰性は3.43%増加してしまった(表1-右)。
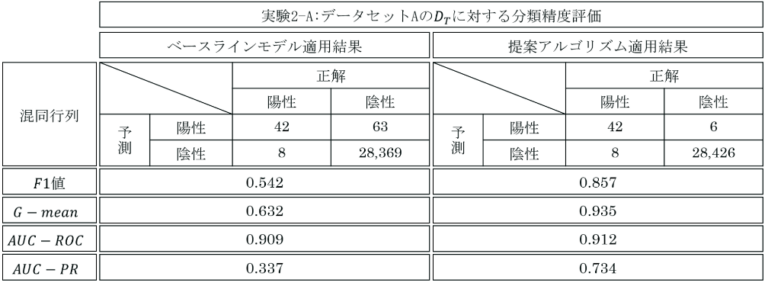
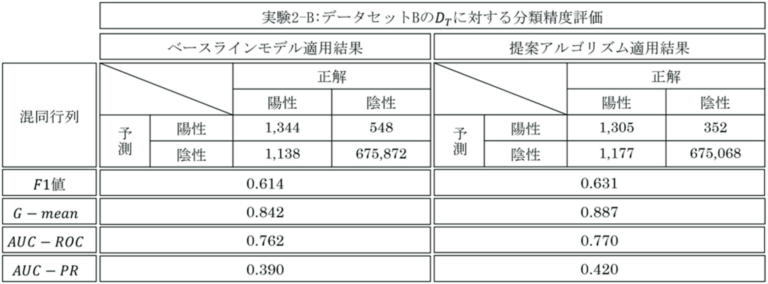
両データセットにおいて、提案手法が全ての評価指標において既存手法を上回った。分類精度向上は、期待していた偽陽性の減少によるものであると考える。
識別関数の評価にF値とG−mean(適合率と特異度の幾何平均)、識別モデルの評価にAUC-ROCとAUC-PRを用いて評価を行った結果、提案手法が全ての評価指標において既存手法を上回った。
以上より、提案手法の有効性が示された。
この記事は、下記の論文を要約したものです
藤原 和樹(2020)不均衡データに対する多段階学習を用いた分類アルゴリズムの提案とその検証、 2019年度 筑波大学 大学院 博士課程 システム情報工学研究科 修士論文。
後記
- 追加実験としてベースラインモデルと提案アルゴリズムの結果の差について統計的な検証を行いました。また、カテゴリデータの特徴量変換と組み合わせることで更なる精度向上も確認しています。それぞれ、査読付き論文として公開されています。
藤原・繁野・住田 (2019) 不均衡データに対する多段階学習を用いたアンサンブルモデルによる2クラス分類アルゴリズムの提案,、数理モデル化と応用, 12(3), 10-17.
Fujiwara, K., Shigeno, M., and Sumita, U. (2019) A New Approach for Developing Segmentation Algorithms for Strongly Imbalanced Data, IEEE Access, 7, 82970-82977.