

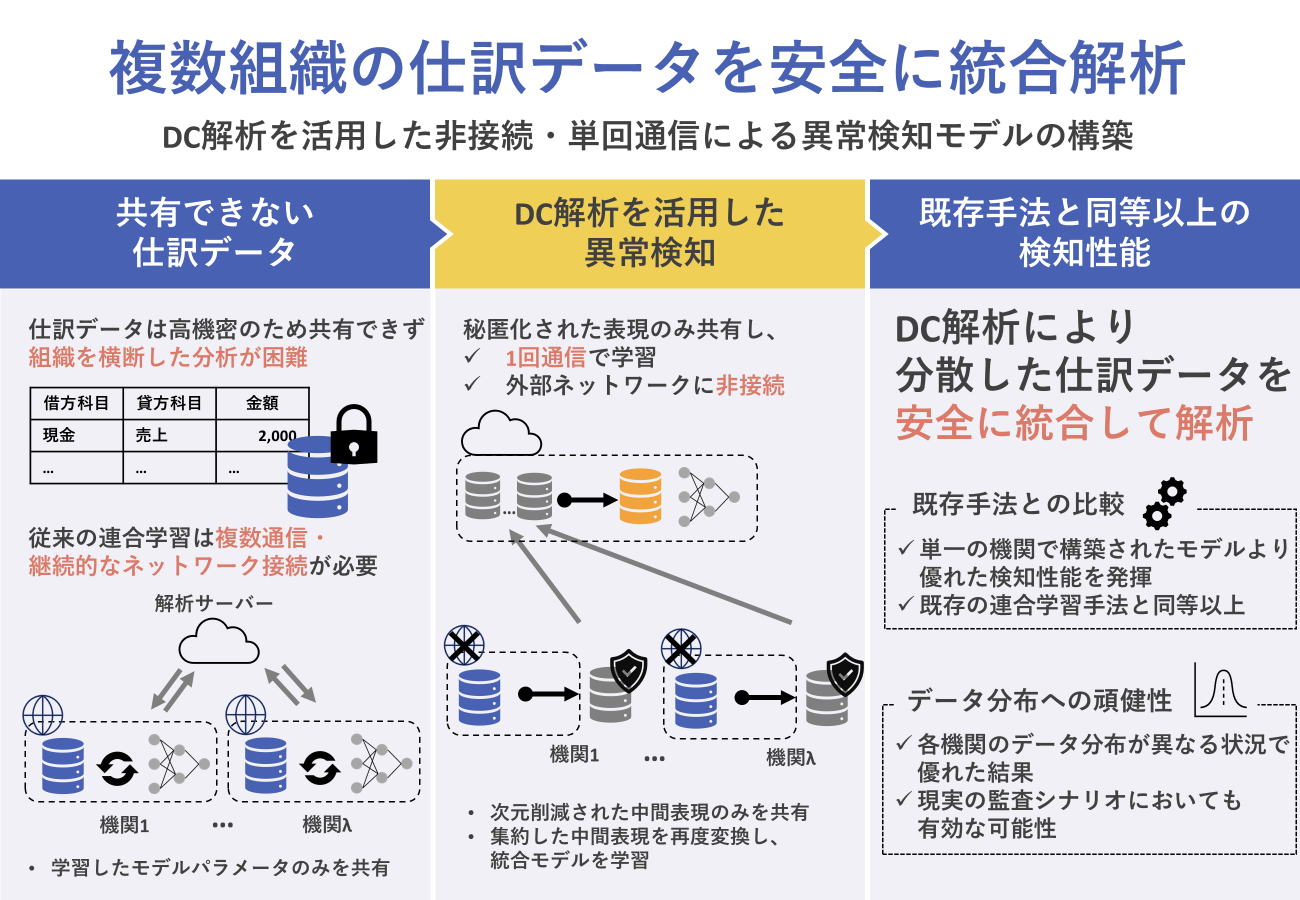
取り組みの概要
背景と課題
監査における仕訳データの重要性
- 仕訳データは、企業活動を記録した詳細な会計データ
- 監査においては、誤謬や不正の発見のために、仕訳データの分析が重要
- 近年、仕訳データに対して機械学習・深層学習を用いた異常検知の活用が進む
複数組織のデータを統合する有効性と課題
- 機械学習や深層学習のモデル学習には、多くのデータが必要
- 監査実務では、同一業種の複数企業を監査することで業界特有の知見が蓄積される
複数組織のデータを統合した分析は有効と考えられる一方で、仕訳データは機密性が極めて高く、組織間で直接共有することは困難である
既存手法の課題
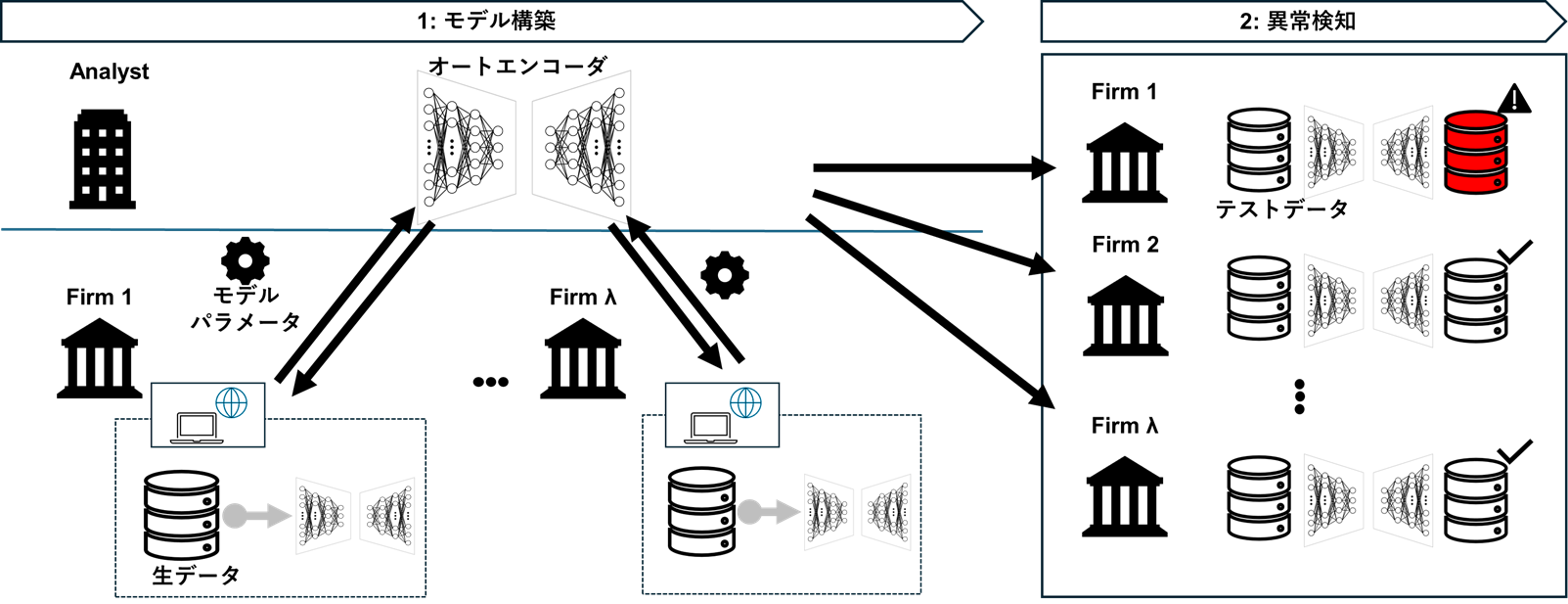
- データを直接共有せずに仕訳異常検知を行う手法ために、連合学習を用いた手法が提案[1]
- 既存の連合学習手法では、外部ネットワークへの接続や複数回の通信が前提
セキュリティ制約の厳しい監査実務環境では、実装が難しい
提案手法
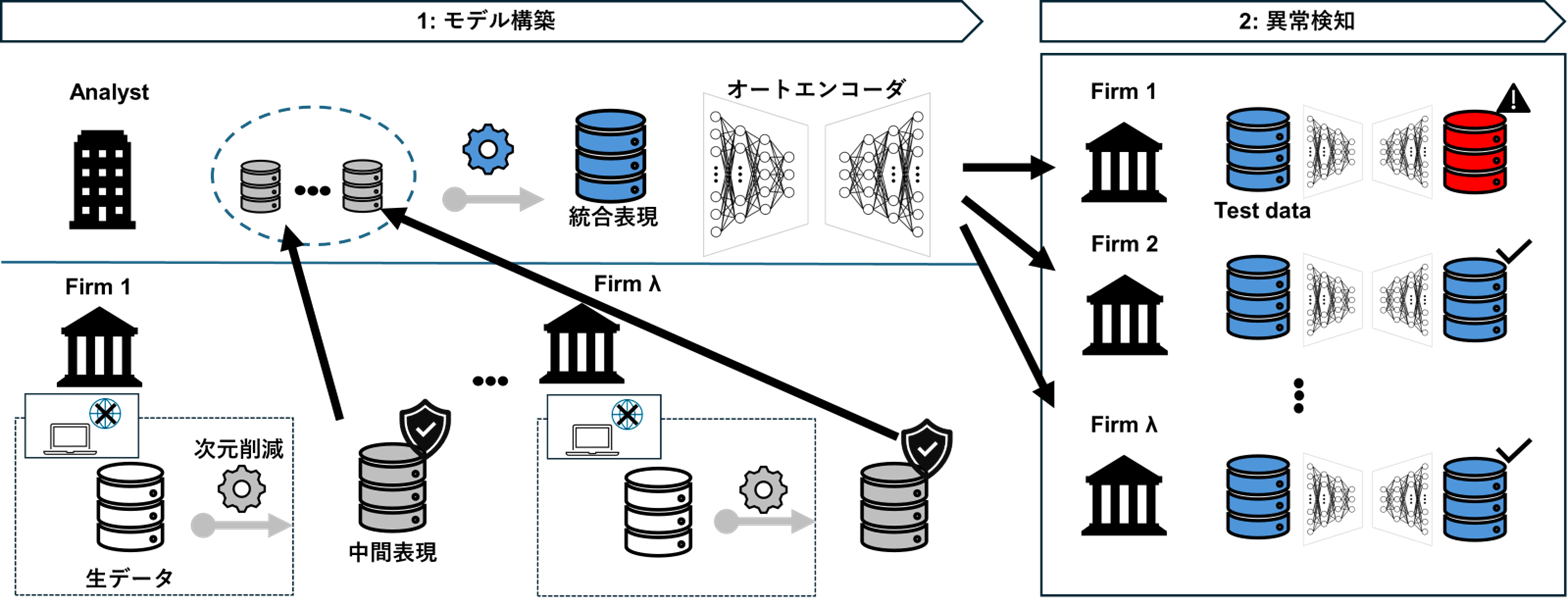
本研究では、複数組織に分散した仕訳データを直接共有することなく、異常検知モデルの性能向上を図るために、Data Collaboration(DC)解析[2]を用いた新しい異常検知手法を採用する。本手法の基本的な発想は、データや学習済みモデルを共有するのではなく、各組織が次元削減によって作成した元の仕訳内容を直接復元できない中間表現のみを用いてデータを統合する点にある。
提案手法の流れ
- 各組織が保有する仕訳データを組織内で前処理・次元削減し、共有可能な中間表現に変換
- 中間表現を集約し、解析可能な統合表現に変換
- 統合表現を使用し、異常検知モデル(オートエンコーダ)を学習
- 学習済みモデルに異常検知を行いたい仕訳データセットの統合表現を入力し、異常検知
本手法の特徴
- 仕訳データの生データは組織外に出ない
→ 取引内容や金額などの機密情報を保護したまま分析が可能 - モデル学習に反復的な通信を行わない
→ 共有は単回で完結し、通信コストを抑えられる - 継続的な外部ネットワーク接続を必要としない
→ セキュリティ制約の厳しい監査実務環境にも適用しやすい
| 観点 | 連合学習(FedAvg・FedProx) | 提案手法(DC解析) |
| 共有対象 | モデルパラメータ | 中間表現 |
| 通信回数 | 複数回 | 単回 |
| ネットワーク | 継続接続が前提 | 非接続でも可 |
実験設定
使用データ
共同研究先である税理士法人日本経営から提供された、8つの医療法人の仕訳データを使用する。
- 2016年から2022年までの仕訳データ
- 2021年までのデータをモデル学習に使用
- 2022年の仕訳データを使用して異常検知性能を評価
- 借方勘定科目・貸方科目・金額の3つの特徴量を使用
- 異常データは人工的に作成
- グローバルな異常:単一の特徴量に異常がある
→極端に大きな金額を持つ仕訳を挿入 - ローカルな異常:複数特徴量の組み合わせに異常がある
→勘定科目間や勘定科目と金額
- グローバルな異常:単一の特徴量に異常がある
- データの分割方法を2つの設定で実験
- 独立同分布(i.i.d.):各組織のデータが同様の分布を持つ
- 非独立同分布(non-i.i.d.):組織ごとにデータ分布が異なる状況を想定
→実際の監査環境に近い設定
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| i.i.d. | 12,780 | 12,780 | 12,780 | 12,780 | 12,780 | 12,780 | 12,780 | 12,779 |
| non-i.i.d. | 17,070 | 22,978 | 10,708 | 14,984 | 8,611 | 11,230 | 8,525 | 8,133 |
評価
提案手法の有効性を検証するために、以下の4つの手法との比較を行う
- 個別解析:データを統合せず、単一の構築されたモデル
- FedAvg:一般的な連合学習のアルゴリズム
- FedProx:non-i.i.d.に強い連合学習のアルゴリズム
- 集中解析:生データのまま集約できる理想的な状況を仮定して構築されたモデル
(機密性の観点から現実での実装は難しい)
評価指標はAUPRC(AP)を使用する
- 「異常な仕訳を漏れなく識別できるか」「誤検知を過剰に発生させないか」を同時に評価
- 1に近いほど高い検知性能であることを示す
成果と提案
表3は提案手法と比較手法の結果をまとめたものである。AP allは2種類の異常を総合的に検知する性能を示し、AP globalはグローバルな異常、AP localはローカルな異常を検知する性能を示している。
- DC(PCA)は、単一の機関のデータのみで学習した個別解析を一貫して上回る性能を示した
→複数組織に分散した仕訳データを効果的に統合したモデルが構築できていることが確認された - non-i.i.d.において、個別解析や連合学習を上回る有効性を発揮
→各機関が所有するデータ分布が異なる、現実の監査状況において有効である可能性が示唆された - ローカルな異常については理想的状況である集中解析との間に一定の差が見られ、今後の課題として検知性能のさらなる向上が求められる
本研究では、DC解析を活用し、非接続・単回通信という実務上の利点を備えた新たな異常検知手法を提案し、既存手法と同等以上の検知性能であることを示した。本研究は、監査分野における AI 導入の大きなボトルネックである会計データの機密性の問題に対する一つの解決策を示しており、実務における AI 活用を推進する可能性を有している。
| 設定 | i.i.d. | non-i.i.d. | ||||
| AP | AP all | AP global | AP local | AP all | AP global | AP local |
| 個別解析 | 0.496 | 0.913 | 0.196 | 0.369 | 0.824 | 0.092 |
| FedAvg | 0.614 | 0.813 | 0.375 | 0.491 | 0.936 | 0.187 |
| FedProx | 0.491 | 0.985 | 0.191 | 0.368 | 1.00 | 0.045 |
| DC (PCA) | 0.512 | 1.000 | 0.206 | 0.495 | 0.993 | 0.188 |
| DC (RP) | 0.467 | 1.000 | 0.141 | 0.497 | 1.00 | 0.190 |
| 集中解析 | 0.686 | 0.958 | 0.440 | 0.686 | 0.958 | 0.440 |
後記
本研究に取り組む中で、提案手法の有効性を検証するための実験設計や研究としての貢献の示し方など様々な観点について、多くの方から貴重なアドバイスをいただきました。この場を借りて感謝申し上げます。
研究室に配属されて以降、Data Collaboration 解析の可能性に惹かれ、この手法を用いた研究に取り組みたいと考えてきました。今回、論文として成果をまとめることができたことを、大変うれしく思っています。本研究にはまだ課題も残されていますが、今後は本研究を基盤として、仕訳データの機密性や分散性に着目した研究がさらに発展していくことを願っています。
税理士法人日本経営には、大変貴重な仕訳データのご提供ならびに本研究に関するご助言に、心より感謝申し上げます。
本研究の詳細についてご興味をお持ちの方は、以下の論文をご覧いただけますと幸いです。
Mashiko, S., Kawamata, Y., Nakayama, T., Sakurai, T., & Okada, Y. (2025). Anomaly detection in double-entry bookkeeping data by federated learning system with non-model sharing approach. Scientific Reports, 15(1), 42208.https://www.nature.com/articles/s41598-025-26120-y
本研究は JSPS 科研費 23K22166 の助成を受けたものである。
参考文献
[1]Imakura, A., & Sakurai, T. (2020). Data collaboration analysis framework using centralization of individual intermediate representations for distributed data sets. ASCE-ASME Journal of Risk and Uncertainty in Engineering Systems, Part A: Civil Engineering, 6(2), 04020018.
[2]Schreyer, M., Sattarov, T., & Borth, D. (2022). Federated and privacy-preserving learning of accounting data in financial statement audits. In Proceedings of the Third ACM International Conference on AI in Finance (pp. 105-113).