
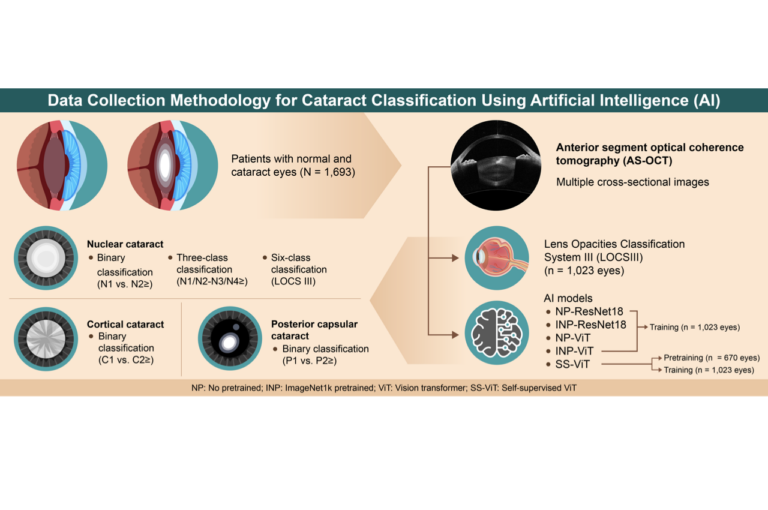
研究の概要

本研究では、前眼部光干渉断層撮影(AS-OCT)画像から白内障の重症度を高精度に分類するための人工知能(AI)システムを開発しました。特に、Vision Transformer(ViT)と自己教師学習を組み合わせることで、従来の手法より優れた分類精度を実現しました。当アプローチは核白内障の6段階分類だけでなく、これまで実現できていなかった皮質白内障・後嚢下白内障も含めた包括的な分類システムを構築することに成功しています。ラベルなしデータを活用した医用画像特有の特徴抽出技術により、限られたラベル付きデータからも高い分類精度を達成した点が本研究の革新的な側面です。
背景と課題
白内障は世界で最も多い視力障害の原因であり、WHO(世界保健機関)の報告によると約6520万人が加齢性白内障による視力障害を抱えています。この数は今後さらに増加すると予測されています。
白内障の重症度分類には一般的にLOCS III(Lens Opacities Classification System III)が標準として用いられています。このシステムでは、核白内障を6段階、皮質白内障と後嚢下白内障をそれぞれ5段階に分類します。眼科医は細隙灯顕微鏡で観察される前眼部の様子をLOCS IIIの基準写真と比較して重症度を判定しています。
近年、白内障診断の標準化と自動化のために、人工知能(AI)を活用した分類システムの開発が進められています。白内障分類AIには主に3つの画像モダリティが使用されています:
- 眼底写真:入手が容易であるものの、白内障部位別の評価ができず、重症度分類の基準が不統一
- 細隙灯顕微鏡写真:臨床実践では標準的だが、撮影環境に影響されやすく標準化が難しい
- 前眼部OCT画像:レンズを含む前眼部の断層画像を取得でき、3次元構造の把握と撮影環境の安定性に優れている
前眼部OCT画像は白内障診断の標準化と自動化において最も有望とされています。これは複数の断面から3次元画像を取得できること、撮影環境が安定していることが主な理由です。しかし、現在の前眼部OCT画像を用いた白内障分類AIには大きな2つの課題があります:
- 分類精度の不足:核白内障の3クラス分類での最高精度は0.893と実用レベルに達していない
- 核白内障のみの分類:皮質白内障や後嚢下白内障を含めた包括的な分類システムが開発されていない
既存研究では、事前処理として核領域のみをクロップして特徴を限定し、ResNetアーキテクチャベースのAIで分類を行っていましたが、この手法では皮質や後嚢下などの他の領域の白内障をターゲットにすることができません。
画像分類の精度向上には事前学習が有効であることが知られています。一般的な画像認識タスクではImageNetデータセットによる事前学習が性能向上に寄与しますが、医用画像(胸部X線など)においてはImageNet事前学習の効果は限定的です。そのため、医用画像の特性に合わせた事前学習手法が必要とされています。
この課題を解決するための有望なアプローチとして、正解ラベルを必要としない自己教師学習があります。特に、Vision Transformer(ViT)をMasked Autoencoder(MAE)と呼ばれる自己教師学習と組み合わせることで、効果的な事前学習が可能になります。本研究では、前眼部OCT画像の白内障重症度分類において、自己教師学習とViTを活用した新たなアプローチを検証しました。
使用データ
本研究では、筑波大学病院眼科で2015年7月から2023年12月の間に収集された1,693眼の前眼部OCT画像を使用しました。撮影には第二世代の前眼部OCTシステムであるCASIA2(トーメー社、日本)を使用し、各眼について0°から360°まで12.5°間隔で回転させながら16枚の断面画像を取得しました。
収集されたデータセットは、以下の2つのコンポーネントに分けられました:
- AS-OCT1023-L:LOCS IIIによる分類が行われた1,023眼のデータ(2020年8月までに撮影)
- AS-OCT670:LOCS III分類のない670眼のデータ(2020年9月以降に撮影)
AS-OCT1023-Lは分類AIの訓練と評価に使用し、4:1の比率で訓練データ(821眼)とテストデータ(202眼)に分割しました。一方、AS-OCT670はViTの自己教師学習のためのデータセットとして活用しました。
データ分析
訓練データにおいて、核白内障、皮質白内障、後嚢下白内障のすべてのカテゴリで顕著なクラス不均衡が見られました:
- 核白内障:69.3%が陽性(N2以上)、重度(N4以上)は10.0%のみ
- 皮質白内障:正常例(C1)が約70%を占める
- 後嚢下白内障:正常例(P1)が約80%を占める
このクラス不均衡に対処するため、評価指標としてArea Under the Precision-Recall Curve(AUPRC)を採用し、データサンプリング手法やFocal Loss、Class Balanced Lossなどの手法を検討しました。
実験環境と前処理
すべての実験はRTX 2080 TiまたはRTX 3080 Ti GPU(NVIDIA社)を搭載したコンピュータで実行しました。オペレーティングシステムはUbuntu 22.04を使用し、データの前処理とセグメンテーションにはScikit-learnとOpenCVを使用しました。
前処理では、AS-OCT画像の周囲に黒い長方形を追加して正方形にし、224×224ピクセルにリサイズしました。入力画像として、水平断面画像のみと全断面画像の両方を評価しました。
タスク設定
本研究では、5つのAIモデルの性能を評価するために以下の5つのタスクを設定しました:
- 核白内障2クラス分類:LOCS III N1を陰性(クラス1)、N2以上を陽性(クラス2)と定義
- 核白内障3クラス分類:N1を無症状(クラス1)、N2・N3を軽度疾患群(クラス2)、N4以上を重度疾患群(クラス3)と定義
- 核白内障6クラス分類:LOCS IIIと同じ6段階の分類
- 皮質白内障2クラス分類:C1を陰性(クラス1)、C2以上を陽性(クラス2)と定義
- 後嚢下白内障2クラス分類:P1を陰性(クラス1)、P2以上を陽性(クラス2)と定義
核白内障については、既存研究との比較を容易にするために、先行研究で実施されたすべての分類タスク(2クラス、3クラス、6クラス分類)を実装しました。皮質白内障と後嚢下白内障については、先行研究がないため、まず基本的な2クラス分類を検証しました。
分類モデル
各タスクに対して、5つのAIモデルを開発し、テストデータで性能を評価しました:
- 事前学習なしResNet18(NP-ResNet18)
- 事前学習なしVision Transformer(NP-ViT)
- ImageNet事前学習ResNet18(INP-ResNet18)
- ImageNet事前学習Vision Transformer(INP-ViT)
- 自己教師学習Vision Transformer(SS-ViT):AS-OCT670を使用した自己教師学習
SS-ViTモデルでは、Masked Autoencoder(MAE)と呼ばれる自己教師学習手法を採用しました。この手法では、入力画像の一部をマスクし、マスクされた部分を予測するようにモデルを訓練します。これにより、ラベルなしデータからも効果的に特徴を学習することができます。
クラス不均衡に対処するため、主要な評価指標としてAUPRCを使用し、比較のためにAccuracyとAUROCも記録しました。3クラス以上の分類では、マクロ平均を計算しました。
成果と提案
核白内障2クラス分類
核白内障の2クラス分類では、すべてのAIモデルが事前学習の種類に関わらず高い分類性能を示しました。ImageNet事前学習モデル(INP-ResNet、INP-ViT)とSS-ViTはいずれも0.999の最高AUPRCを達成しました。これらのモデルはAUROCとAccuracyの面でも高い性能を示しました。最良のモデルは202ケース中196ケース(97.0%)を正しく分類し、特に陽性クラスでは157ケース中156ケース(99.4%)を正確に識別しました。
表1. 核白内障2クラス分類 結果
| Pretraining | Backbone | Model name | AUPRC | AUROC | Accuracy |
| None | ResNet18 | NP-ResNet | 0.998 | 0.994 | 0.960 |
| ImageNet | INP-ResNet | 0.999 | 0.995 | 0.980 | |
| None | ViT | NP-ViT | 0.996 | 0.985 | 0.911 |
| ImageNet | INP-ViT | 0.999 | 0.996 | 0.980 | |
| AS-OCT670 | SS-ViT | 0.999 | 0.995 | 0.970 |
核白内障3クラス分類
核白内障の3カテゴリへの分類では、モデル間で性能に差が見られました。SS-ViTモデルはAUPRC 0.939と最高性能を示し、NP-ResNetモデルもAUPRC 0.909と比較的高い性能を発揮しました。一方、ImageNet事前学習モデル(INP-ResNetとINP-ViT)はAUPRCが0.894以下となり、特にINP-ViTモデルは0.745と低いAccuracyを示しました。
最も性能の高いモデルは202ケース中186ケース(92.1%)を正確に分類し、特にN2とN3の中間群では139ケース中138ケース(99.3%)を正しく識別しました。しかし、重度群(≥N4)では18ケース中8ケース(44.4%)が誤分類されました。
各クラスのAUPRCを比較すると、SS-ViTモデルがすべてのクラスで優れた性能を示しました。特に重度群(≥N4)ではSS-ViTがAUPRC 0.844を達成し、他のモデルのAUPRC 0.779以下を大きく上回りました。
表2. 核白内障3クラス分類
| Pretraining | Backbone | Model name | AUPRC | AUROC | Accuracy |
| None | ResNet18 | NP-ResNet | 0.909 | 0.968 | 0.901 |
| ImageNet | INP-ResNet | 0.894 | 0.965 | 0.916 | |
| None | ViT | NP-ViT | 0.855 | 0.948 | 0.827 |
| ImageNet | INP-ViT | 0.876 | 0.953 | 0.745 | |
| AS-OCT670 | SS-ViT | 0.939 | 0.978 | 0.921 |
核白内障6クラス分類
核白内障の6クラス分類では、クラス数の増加に伴いすべてのモデルの性能が低下しました。これらのモデルの中で、SS-ViTは0.788という最高のAUPRCを達成し、INP-ResNetは0.627のAUPRCを記録しました。事前学習なしのモデル(NP-ResNetとNP-ViT)は0.589以下のAUPRCを示しました。
混同行列によると、最良のモデルはN1-N3の軽度から中等度のケースで高い分類精度を示しました。具体的には、N1の39ケースすべて(100%)、N2の73ケース中47ケース(64.4%)、N3の66ケース中54ケース(81.8%)が正しく分類されました。一方、N4以上の重度のケースでは正確な分類が困難であり、特にN5とN6クラスでは大部分が正しく分類されませんでした。
表3. 核白内障6クラス分類
| Pretraining | Backbone | Model name | AUPRC | AUROC | Accuracy |
| None | ResNet18 | NP-ResNet | 0.562 | 0.918 | 0.624 |
| ImageNet | INP-ResNet | 0.627 | 0.911 | 0.629 | |
| None | ViT | NP-ViT | 0.589 | 0.891 | 0.550 |
| ImageNet | INP-ViT | 0.444 | 0.760 | 0.812 | |
| AS-OCT670 | SS-ViT | 0.788 | 0.947 | 0.757 |
皮質白内障2クラス分類
皮質白内障の2クラス分類では、すべてのモデルが核白内障の2クラス分類よりも性能が低下しました。中でもSS-ViTが0.751という最高のAUPRCを達成し、次いでNP-ResNetが0.747のAUPRCを記録しました。一方、ViTベースのモデル(NP-ViTとINP-ViT)は0.736以下のAccuracyと比較的低い性能を示しました。最良のモデルは202ケース中156ケース(77.2%)を正しく分類しました。
表4. 皮質白内障2クラス分類
| Pretraining | Backbone | Model name | AUPRC | AUROC | Accuracy |
| None | ResNet18 | NP-ResNet | 0.747 | 0.841 | 0.757 |
| ImageNet | INP-ResNet | 0.727 | 0.836 | 0.757 | |
| None | ViT | NP-ViT | 0.536 | 0.733 | 0.733 |
| ImageNet | INP-ViT | 0.737 | 0.736 | 0.713 | |
| AS-OCT670 | SS-ViT | 0.751 | 0.860 | 0.772 |
後嚢下白内障2クラス分類
後嚢下白内障の2クラス分類では、すべてのモデルでAUPRCが低下しました。具体的には、最高性能のSS-ViTでも0.506に留まりました。特に、NP-ViTとINP-ViTは0.287から0.444の低いAUPRC値を示した一方、Accuracyは0.812と高い値を記録し、評価指標間で一貫性のない結果となりました。
混同行列を見ると、最良のモデルはP1陰性クラスで164ケース中156ケース(95.1%)という高い検出率を示しましたが、P2以上の陽性クラスでは38ケース中12ケース(31.6%)しか正しく分類されず、クラス間で大きな性能差が見られました。
表5. 後嚢白内障2クラス分類
| Pretraining | Backbone | Model name | AUPRC | AUROC | Accuracy |
| None | ResNet18 | NP-ResNet | 0.396 | 0.730 | 0.787 |
| ImageNet | INP-ResNet | 0.456 | 0.727 | 0.811 | |
| None | ViT | NP-ViT | 0.287 | 0.635 | 0.812 |
| ImageNet | INP-ViT | 0.444 | 0.760 | 0.812 | |
| AS-OCT670 | SS-ViT | 0.506 | 0.762 | 0.832 |
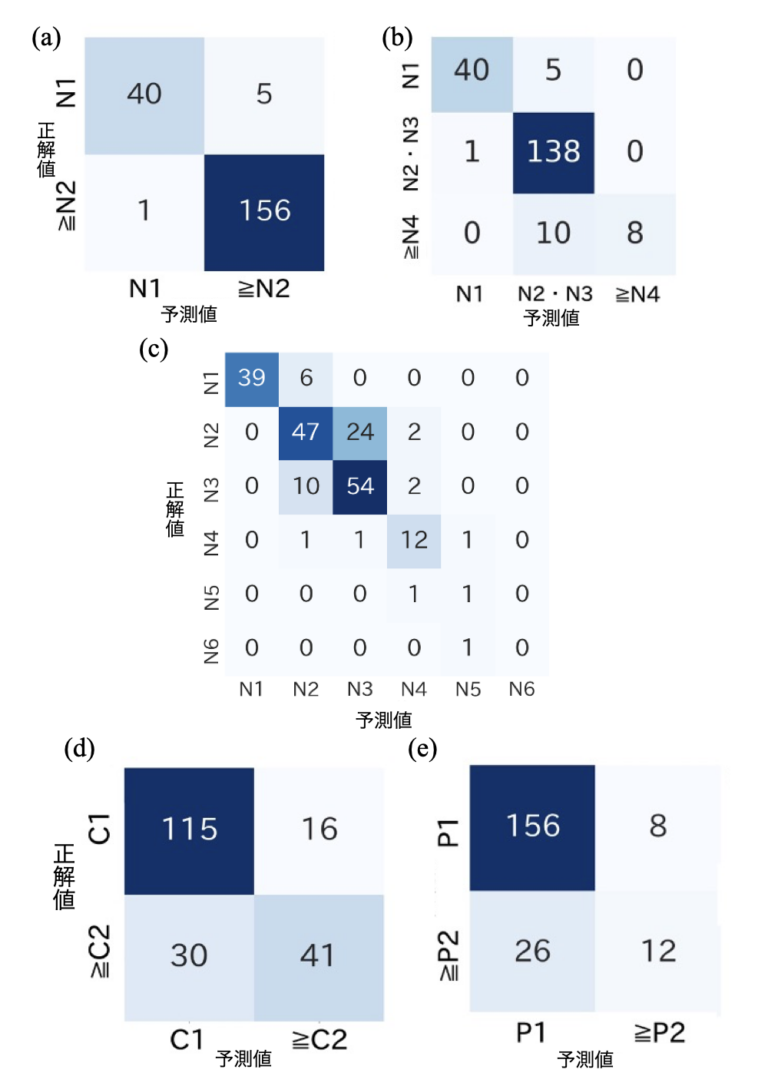
図1. ベストモデルの混同行列
考察
本研究により、AS-OCT670を用いた自己教師学習が、前眼部OCT画像を使用した白内障重症度評価の分類精度を大幅に向上させることが示されました。SS-ViTモデルは、核白内障2クラス分類でAUPRC 0.999、3クラス分類でAUPRC 0.939、6クラス分類でAUPRC 0.788という最高性能を達成しました。特に、3クラス分類の重度群(≥N4)ではAUPRC 0.844と他のモデルを上回り、6クラス分類のN1-N3の軽度から中等度のクラスでも優れた性能を維持しました。加えて、SS-ViTは皮質白内障と後嚢下白内障の分類でもAUPRC 0.751と0.506という最良の性能を記録しました。
自己教師学習の有用性は、白内障診断において2つの重要な意味を持っています:
- AS-OCT670を用いた自己教師学習は、AS-OCT画像特有の構造と特徴を効果的に抽出できます。AS-OCTなどの医用画像は独特の特性を持ち、従来のImageNetによる事前学習では十分に強化できない可能性があります。本研究の特徴抽出プロセスは、ImageNetを用いた一般的な画像による事前学習よりも医用画像に適していることが示唆されます。
- この手法は、核白内障の重度例や皮質白内障など、様々なタイプの白内障分類に効果的です。これは、ラベル付きデータが限られていても、AS-OCT画像のみを使用して効率的なトレーニングが可能であることを意味します。本研究で示されたように、ラベルなしデータセットを事前学習に使用することで、モデルのパフォーマンスを効率的に向上させることができます。
先行研究と比較すると、本研究のSS-ViTはより包括的で正確な白内障分類を提供しています。Zhang et al.の先行研究では、核白内障3クラス分類で0.893の精度を達成していましたが、核のみを対象としていました。一方、本研究のSS-ViTは核白内障3クラス分類で0.921の精度を達成しただけでなく、皮質白内障の分類も可能にしました。さらに、SS-ViTは核白内障2クラス分類で0.970の精度を達成し、先行研究の0.945を上回りました。
今後の課題としては、本研究で使用したデータセットが単一施設に限定されているため、今後は多様な人種や年齢層にわたる検証が必要です。また、本研究の自己教師学習モデルは皮質白内障の分類において比較的最適な性能を示していないため、分類精度のさらなる向上の余地があります。これらの限界は、大規模な多施設データ収集、複数の眼科医による評価基準の標準化、特に皮質白内障を含むより多様なケースの収集によって、モデルの一般化可能性と信頼性を向上させることで対処できるでしょう。
レファレンス
- World Health Organization. World report on vision. World Health Organization; 2019.
- Chylack LT Jr, et al. The Lens Opacities Classification System III. Arch Ophthalmol. 1993;111:831-836.
- Zhang X, et al. Attention to region: Region-based integration-and-recalibration networks for nuclear cataract classification using AS-OCT images. Med Image Anal. 2022;80:102499.
- Dosovitskiy A, et al. An image is worth 16×16 words: Transformers for image recognition at scale. ICLR. 2021.
- He K, et al. Masked autoencoders are scalable vision learners. CVPR. 2022:16000-16009.
後記
本研究を通じて、医用画像分野における自己教師学習の可能性を実感しました。白内障分類という具体的な応用例を通じて、ラベルなしデータの活用がいかに効果的であるかを示すことができたのは大きな成果です。
また、医用画像特有の特徴を抽出するための自己教師学習の実装にも苦労しました。単なる教師あり学習よりもコードの実装に工夫が必要なので、書くのに時間がかかりました。
本研究を通じて理化学研究所の医療データ深層学習チームと共同研究を出来たのは非常に良い経験でした。研究の進め方やまとめ方、発表方法など大学院生として必須の技術に磨きをかけることができました。また、筑波大学眼科の先生方にも大変お世話になりました。