
研究の概要
背景と課題
人間と関わるロボットの研究は古くから行われており、近年は感情表現を伴って人間とコミュニケーションするロボットの研究が進んでいる。人間とロボットが協働して作業するような場合には、ロボットによる感情表現のフィードバックが人間との関係にポジティブな影響を与えることが知られている。
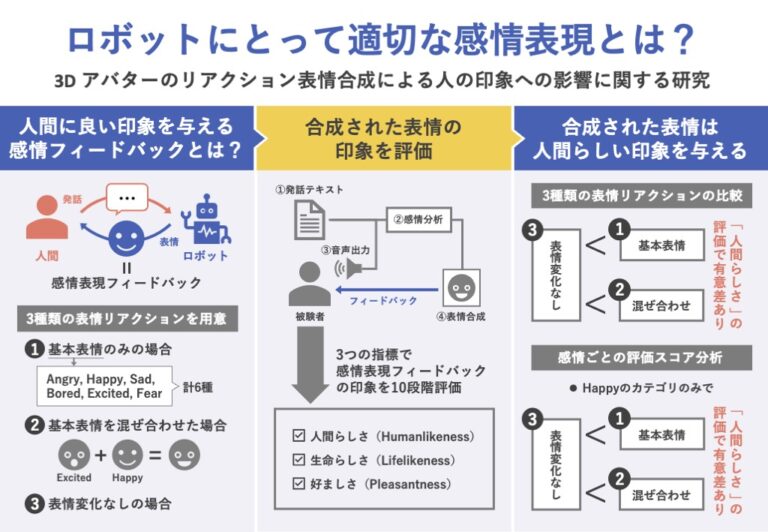
本研究は、人間のような見た目をしたバーチャルエージェントの感情表現を、特に表情に絞って分析し、人間に良い印象を与えるための表情リアクションの合成方法を明らかにすることである。
本研究の特徴は、複数の基本表情を混ぜ合わせた表情合成のパターンを用意するという点である。例えば、“I can’t wait for mom to slap his hand down”と“Finally something nice”という2つの発話スクリプトは、感情分析すると最大成分はどちらもExcited(興奮)となるが、2番目に大きい成分は前者ではAngry(怒り)、後者ではHappy(幸せ)となる。本研究では、最大成分以外の感情を表情に反映させるため、表情を混ぜ合わせる。
測定に使う指標は先行研究(Mukashev et al. 2021)の実験に基づき、次の3つとする。
- Humanlikeness(人間らしさ)
バーチャルエージェントがどれだけ人間らしい表情のリアクションであるかを評価するための指標 - Lifelikeness(生命らしさ)
バーチャルエージェントがどれだけ生き物のように感じられるかを評価する指標 - Pleasantness(好ましさ)
バーチャルエージェントに対してどれだけ好ましい印象を感じられるかを評価する指標
これらの指標を用いて印象を測定し、3つの表情合成パターンを評価し、発話に対するロボットの適切な表情リアクションを明らかにする。この研究によって得られた考察を応用することによって、実際の現場で人間とコミュニケーションするロボットの適切な表情合成が可能になると考えられる。
実装
発話スクリプトをテキストデータとして入力し、感情分析を行い、分析結果である感情パラメータに対応した表情をバーチャルエージェントに出力させる。表情リアクションパターンとして、基本表情(Unblended)、基本表情が混ぜ合わされた表情(Blended)、変化しない表情(Unchanged)の3つを用意する。
人間の発話には感情を伴った情報が伝達されるが、文章からそのまま感情を推測することはコンピュータには困難である。そこで、本研究ではKomprehendによるEmotion Analysisを用いて感情分析を行うこととした。
Emotion Analysisでは、テキストを入力として与えると、感情ごとの確率(信頼度)が出力される。例えば、“Happy new year!”を入力すると、Angry(怒り)の感情の成分が約0.044、Happy(幸せ)の感情の成分が約0.394と出力される。
バーチャルエージェントのリアクション表情合成にはUnityを使用し、アバターとしてVRoid StudioのAvatarSample Aを採用した。Unityには、ブレンドシェイプと呼ばれるモデルのメッシュの頂点をパラメータによって変動させることができる機能が搭載されている。そこで、採用したアバターに搭載されているブレンドシェイプ・パラメータを調整し、Emotion Analysisの出力に対応する感情を表す基本表情、幸せ、怒り、悲しみ、興奮、恐怖、退屈を用意した(図1)。
Unblendedでは、感情分析済みのテキストの感情パラメータを受け取り、その中で最も確率の高い感情の基本表情を合成する。Blendedでは、感情分析済みのテキストの感情パラメータを受け取り、ブレンドシェイプによって基本表情を混ぜ合わせることによって表情合成を行う(図2)。


(左: パラメータに対応して混ぜ合わされた表情、右: 発話スクリプトと感情分析されたパラメータ)
評価実験
評価実験の準備として、人間の発話スクリプトの用意と音声の生成を行い、UnityのUnity Recorderを使用し実験動画となる実行画面の録画を行った。録画した動画は表情合成パターンごとに1200個であり、合計3600個の動画を用意した。表情合成パターンの違いによる影響を測定するため、同じスクリプトでのBlendedとUnblendedとUnchangedの動画を相対評価するように実験を構成した。評価実験はAmazon Mechanical Turkを用いて行う。
実験動画の用意
本研究では、発話のためのスクリプトが必要である。そこで、GoEmotions(58,000件のRedditコメントに対して27の感情カテゴリがラベル付けされたデータセット)を採用した。このデータセットの感情カテゴリから、本研究で選択した6つの感情カテゴリと対応するコメントに絞り、各感情カテゴリに対して200件のコメントをランダムに抽出し、合計1200件のスクリプトとして用意した。
発話音声を作成するために、MacOSに搭載されたsayコマンドを用いて、発話スクリプトを読み上げさせた。比較的滑らかな読み上げを評価し声の種類としてAvaを採用した。
実験動画は、Unity上の実行画面を録画することにより作成した。発話スクリプトの音声再生後に、発話スクリプトに応じたリアクション表情の合成を行う。各音声の開始前と終了後には2秒間のバッファを用意した。実際の動画の流れは、2秒間の空白、音声再生、音声終了と同時に表情変化、2秒間の空白となっている。
Amazon Mechanical Turkのタスク設計
Amazon Mechanical Turk (AMT)とは、Amazon Web Serviceが提供するクラウドソーシングのサービスである。依頼したい様々なタスクをワーカーと呼ばれる作業者に依頼することができる。本研究の実験ではAMTを用いて、事前に用意した動画について評価してもらうようなタスクを設計し、クラウドソーシングを実施した。
発話スクリプトが同一である、表情合成パターンの異なる3つの動画について、相対評価により回答してもらうタスクとした。評価には3つの指標のそれぞれについて10段階評価をしてもらうよう設計した(図3)。また、タスクごとに3人のワーカーを割り当てるよう設定し、合計で3600件の評価を集計した。
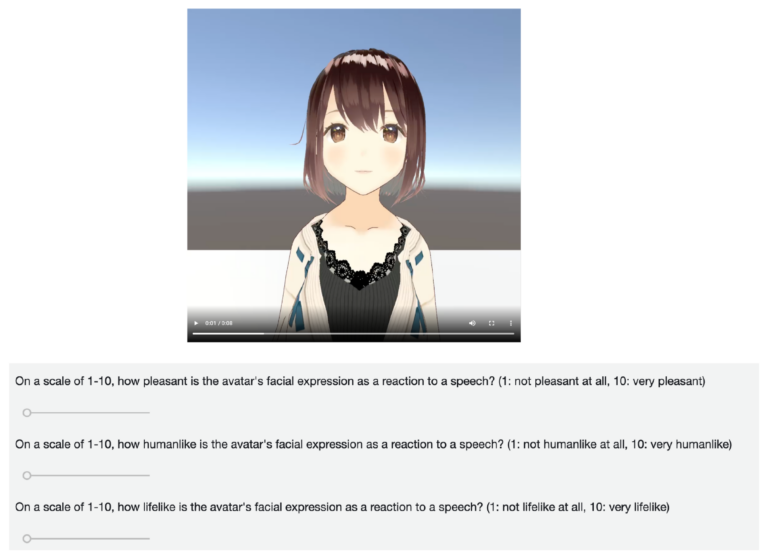
(上: 発話に対して表情を合成するバーチャルエージェントの動画が再生され、
下: スライダーにより10段階評価ができる)
実験結果
AMTによって得られた回答を、R言語を用いて分析した。はじめに3つの指標ごとに、BlendedとUnblendedとUnchangedの差を比較するため、分散分析および多重比較を行った。さらに、感情カテゴリによる評価の違いを検証するため、感情ごとの評価スコア分析も行った。
表情合成パターン間での3つの測定指標ごとの分散分析を行ったところ、Humanlikenessの評価が有意(有意水準5%)であった。そこで、Humanlikenessの評価に関して、表情合成パターン間での多重比較を行ったところ、UnchangedとBlended、UnchangedとUnblendedの間には有意差があることが示された。
続いて、感情ごとの評価スコアを分析した結果、Happyの感情カテゴリにおけるHumanlikenessの評価が有意だった。そこで、HappyにおけるHumanlikenessの評価に対して、表情合成パターン間での多重比較を行ったところ、UnchangedとBlended、UnchangedとUnblendedの間には有意差があることが示された。
議論と結論
本研究では、発話に対するバーチャルエージェントの表情リアクションについて、複数の表情合成パターンの実装と印象に対する評価実験を行った。感情分析によって得られる感情パラメータをもとに基本表情を混ぜ合わせて表出する表情合成パターン(Blended)を作成した。
実験結果の分散分析により、BlendedとUnblendedは、Unchangedに対してHumanlikenessの評価に有意差があることが判明した。この結果から、バーチャルエージェントの表情変化は、人間らしい印象を与えることが考察できる。ロボットによるリアクション変化が人間に対して印象の変化を与える可能性があると示唆された。
また、BlendedとUnblendedとの間には3つの測定指標において有意差は認められなかった。このことは、複雑な表情リアクションと単純にカテゴライズされた表情リアクションには人間らしさや生き物らしさ、好ましさの印象の違いは感じられないということが考察できる。
他の感情カテゴリと測定指標の分析の結果より、Happyのような喜びを表現する発話スクリプトでは、他の感情カテゴリに対し、表情変化が印象に影響を与えやすい可能性があることが示唆された。
本研究により、人間らしい印象を与えるロボットの表情合成方法が示された。この方法は、介護福祉施設や教育現場などにおける、会話の相手としてのロボットや、人間と協力してタスクをこなすロボット等の表情合成の実装に貢献し得ると考えられる。