

概要

背景と目的
- つくば市の運営する「つくチャリ」は、つくば市の公共交通を補完する新しい移動手段であるシェアサイクルサービスである
- 2021年10月1日から2024年9月30日まで実証実験を行なっていたが、収益赤字という問題が生じているため、長期的に地域を支える持続可能な事業に向けて、収益改善の必要がある
- 現状の収支(図1)により,本研究は2,000円/日の収益増加量を目指した
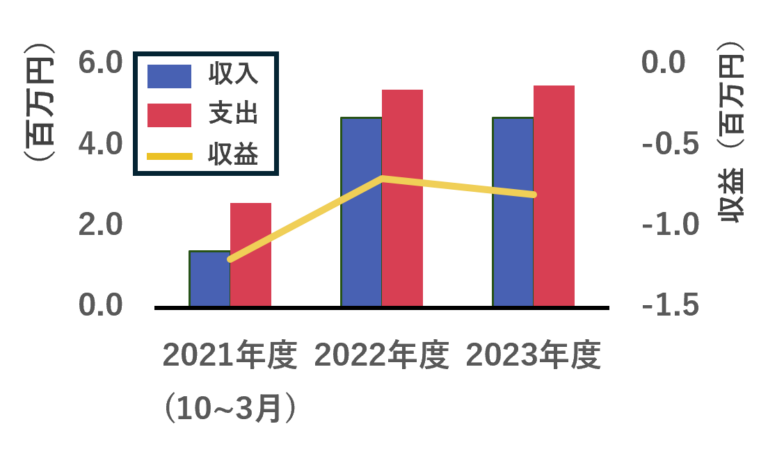
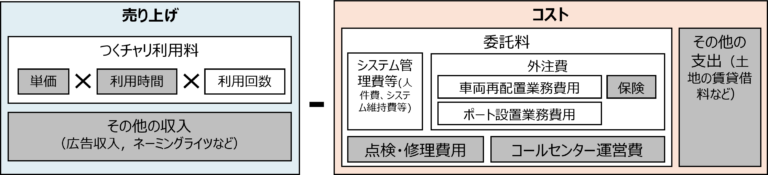
つくチャリの収益構造(図2)を整理し、本研究では、二つの研究からアプローチする。
- 一つ目は、ポートの設置場所を適切な位置に変更することで、利用回数の増加を促すことである
- 二つ目は、毎週の再配置車両数を最適化することで、利用回数の機会損失を減らすことである
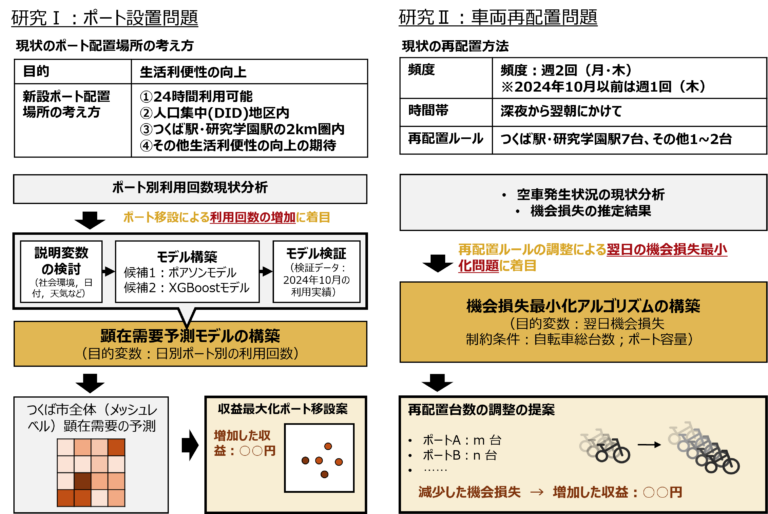
研究の全体像・方法
研究Ⅰ ポート設置場所の提案
- ポアソン回帰モデルとXGBoostモデルを用いて、利用者の利用頻度に影響を与える要因を特定する
- つくば市全体(500mメッシュレベル)の顕在需要を予測し、より収益性のあるポートの設置場所の提案を行う
研究Ⅱ 自転車の再配置作業における各ポートへの自転車の調整台数の提案
- 1時間毎の各ポートにおける自転車の台数を記録し、各ポートの空車(自転車が0台)の発生時間を算出し、現状の再配置作業の効果を把握する
- それらを基に、仮に空車が発生しなかった場合の利用回数(潜在需要)を推定し、実際の利用回数との差から利用者の機会損失を求めた
- さらには、翌日の利用者の機会損失が最小となる自転車の再配置作業の調整台数の最適化問題を解いた
以上の結果から、利用者の機会損失が最小となる自転車の再配置作業の調整台数の提案を行う。
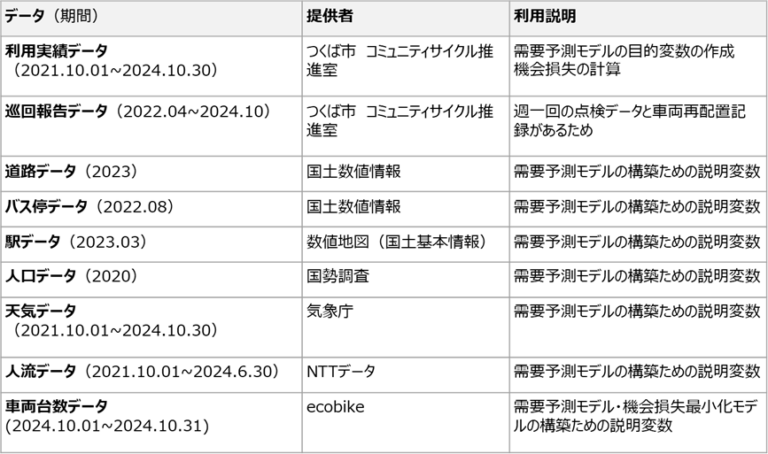
本研究利用したデータは図4となる。
研究結果
研究Ⅰ:ポート設置問題
需要予測モデル使用した変数

候補モデル1:ポアソン回帰モデル
基本的な分析アプローチとして、つくチャリの需要予測モデルにポアソン回帰を採用した。ポアソン回帰は、このような1日に数回~十数回発生するような事象について、需要予測の特徴を適切に捉えることができる統計モデルである。

分析結果
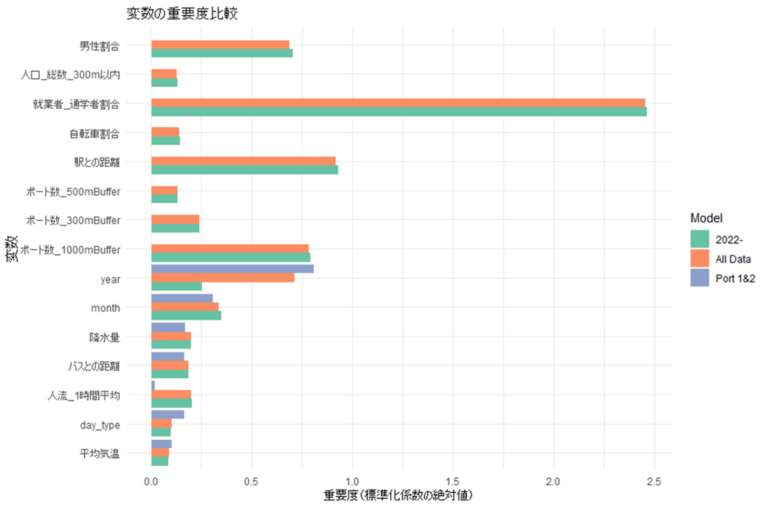
1)変数の係数(図7)
- 就業者・通学者割合が強く効いている
- 駅との距離、1kmポート数も重要な要因
- 曜日や時期による需要変動も確認
2)モデル評価指標:
- RMSE:2.86
- MAE: 1.80
- MAPE: 96.10
候補モデル2:XGBoostモデル
XGBoostは勾配ブースティング法の一種であり、高速な学習と高精度な予測が可能な手法である。特に、非線形な特徴間の関係を学習し、過学習を抑えるための工夫が施されている。XGBoostモデル構築においては、以下のような処理を行った:
- データの前処理:カテゴリ変数である「週末/祝日フラグ」を数値に変換し、標準化を行うことで、特徴量間のスケールの違いを調整した
- 特徴量選択:重要度分析を通じて予測への寄与が少ない特徴量を除去し、必要な変数に絞り込んだ
- 5分割交差検証:モデルの汎化性能を向上させるため、学習データを5つのグループに分けて交差検証を実施し、過学習を抑制した
分析結果
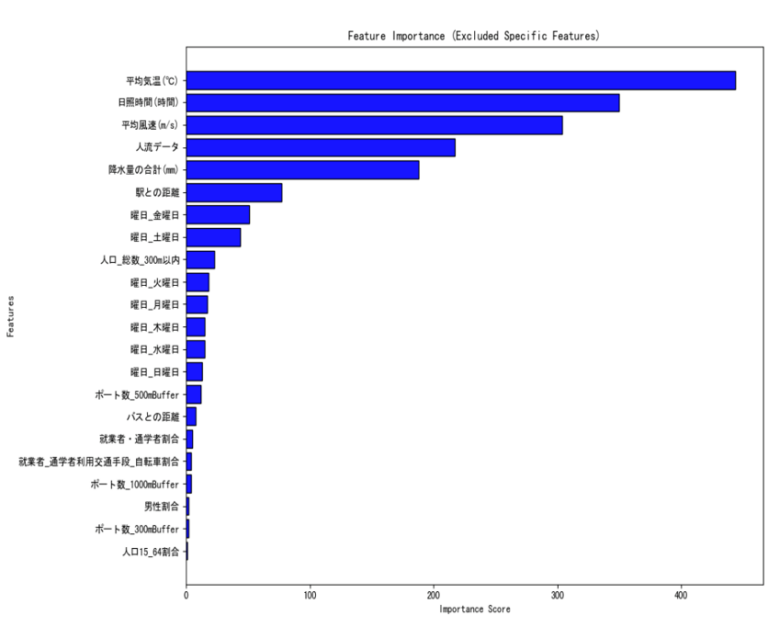
変数の重要度(図8)
- 天気に関する変数以外、人流が強く効いている
- 駅との距離も重要な要因
モデル評価指標:
- RMSE: 1.63
- MAE: 1.34
- R2: 0.8024
候補モデルの比較
- XGBoost モデルの方がポアソン回帰モデルより RMSE・MAE・MAPE の各誤差指標が小さく、より高精度であることが確認できた
ポート移設提案
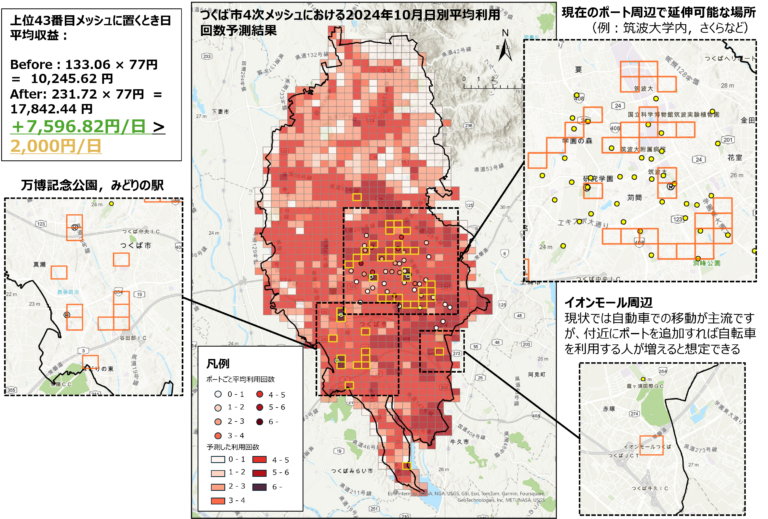
- XGBoostモデルを利用した上位43番目候補地(図9)の収益は7,596.82円/日(>2,000円/日)
- 需要予測モデルの予測結果より,構築利用回数のポテンシャルを考慮して移設を行えば、赤字問題の解消が期待できる
研究Ⅱ:車両再配置問題
自転車台数の現状分析
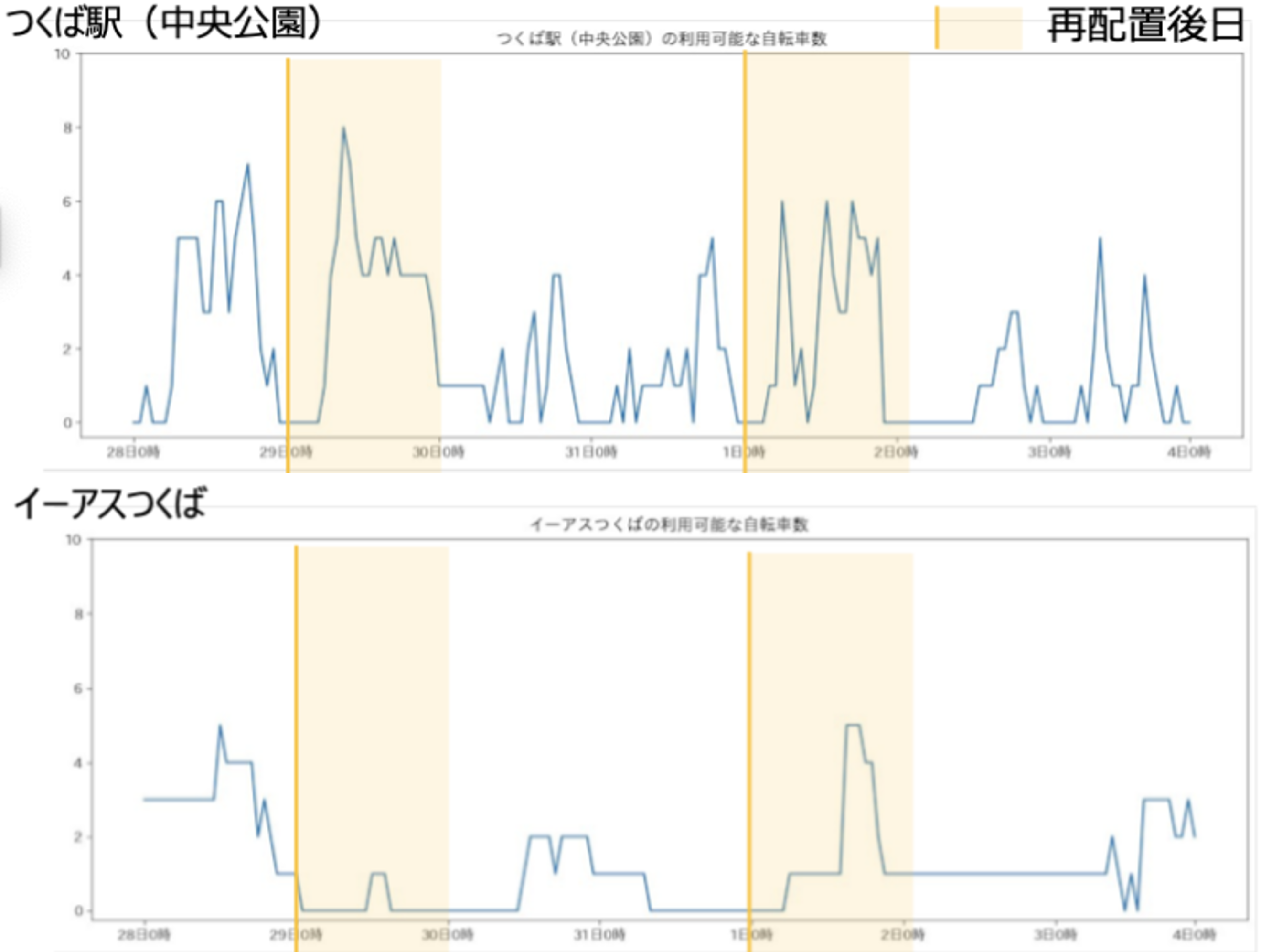
- ポート別の利用データから自転車台数の現状分析(図10)を行ったところ、空車(ポートにおける自転車数が0)の状況が多く見られた
- また、自転車再配置の効果翌々日以降にはあまり影響していないと仮定し、再配置翌日の空車数に着目した
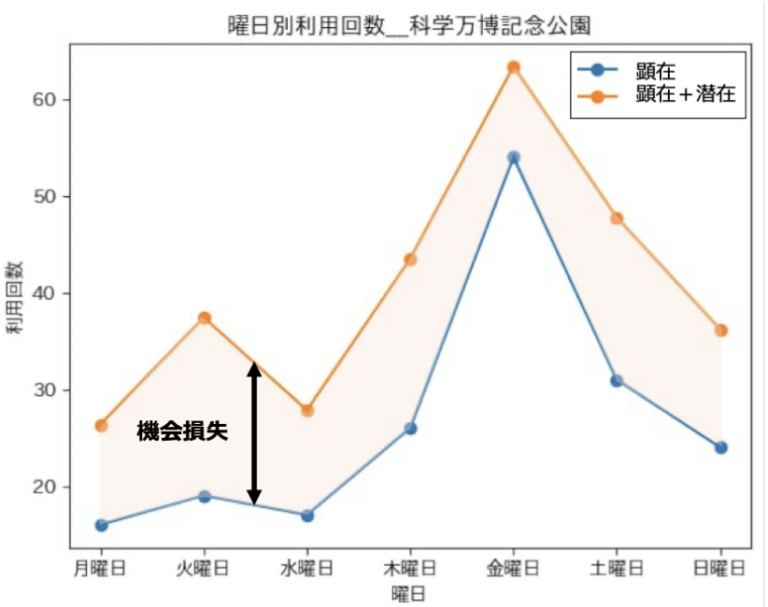
機会損失概念説明
ポート別同じ空車数でも機会損失は異なるため,最小化の対象を空車による機会損失と定義(図11, 図12)

最適化問題の解決案
最適化問題の解決案のプロセス(図13)は以下となる:
- 各ポートのデータ(ポートID、容量、自転車台数、機会損失など)を整理し、次に機会損失を二次関数で近似する(図14)
- そして、自転車の総数が83台であること、自転車台数が各ポートの容量を超えないこと、自転車台数が1以上の整数であることを制約条件を設定する
- SLSQPアルゴリズムを使用し機会損失の合計を最小化する最適化問題を解く

最適化問題の提案
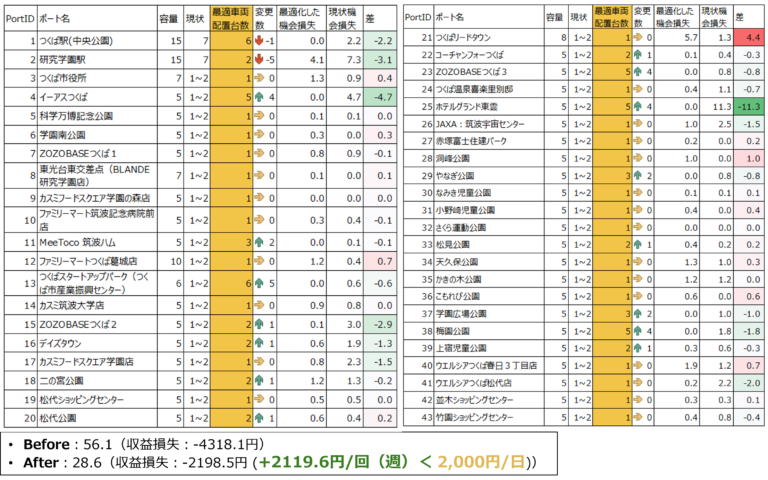
43個ポートの最適車両配置台数の提案は図15に示している
- 自転車台数とポート容量の制約により、損失を完全に0にすることはできない
- 再配置前の収益損失は56.1(-4318.1円/回)でしたが、再配置後は28.6(-2198.5円/回)となり、約2119.6円/回(週2回再配置のため、2,000円/日のゴールより少ない)の改善が見られたが、本施策のみは赤字問題の解決には至っていない
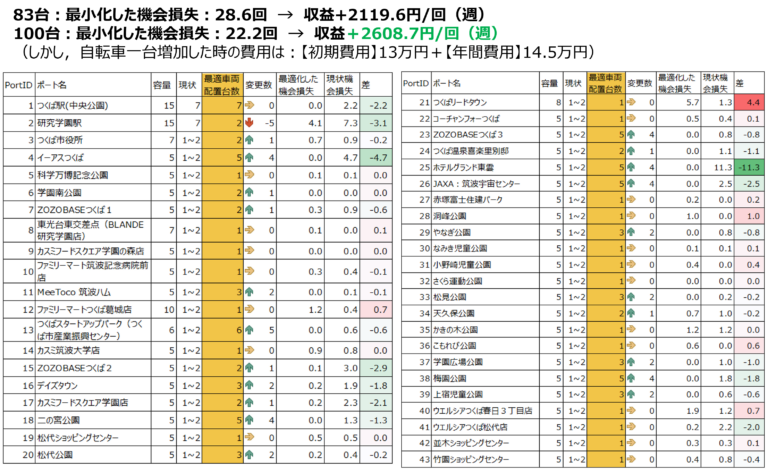
仮に自転車の上限を83台から100台に増やした場合(図16):
- 自転車を増やすことで、機会損失が減少し、収益は週あたり+2119.6円から+2608.7円に向上した
- ただし、追加の自転車には初期費用13万円と年間維持費14.5万円がかかるため、収益とコストのバランスを考慮する必要があり
まとめ
研究Ⅰ:ポート配置問題
- 結論:ポートの移設より,赤字問題の解消は期待される
- つくば市への提案
- ポート配置はDIDだけでなく,人口属性と人流数も考慮するべき
- つくば駅や研究学園駅に加え、万博記念公園駅やみどりの駅への延伸の検討も可能
研究Ⅱ:車両再配置問題
- 結論:再配置台数の調整のみでは一定の効果はあるものの、赤字問題の解消は難しい
- つくば市への提案
- 収益増加には、空車問題の解消を重視するべき
- 再配置自転車台数の設定は、駅タイプだけでなく、利用パターン(例:返却型、貸出型)も考慮するべき
- 機会損失を減少させるためには、自転車総台数、ポート容量、再配置頻度の調整を組み合わせて実施するべき
- 研究Ⅰの結果から、利用回数は天気の影響を強く受けることが分かったため、天候を考慮した動的な再配置案も考慮するべき
課題・今後の予定
- ポート設置場所の提案はポート間の空間特性を考慮し,ポート移設の実施提案(どの移設元からどの移設先まで)の検討(研究Ⅰ)
- 機会損失の推定式の精度の増進はより現実に合わせた車両配置案の検討(研究Ⅱ)
- 車両配置案の提案は満車の問題も考慮(研究Ⅱ)
- 研究Ⅰの需要予測モデルと研究Ⅱの最適化モデルを統合し、シミュレーションシステムを構築することで、ポート配置案と連携した車両再配置案の作成までを提案・実現
参考文献
- 須永大介, 谷下雅義, & 原田昇. (2022). COVID-19 流行前後での札幌市都心部の外出・移動行動およびシェアサイクル利用の変化. 土木学会論文集 D3 (土木計画学), 78(6), II_603-II_612.
- 佐藤仁美, 酒井良輔, 三輪富生, & 森川高行. (2013). コミュニティサイクルシステムの利用実態とステーション配置に関する研究. 土木学会論文集 D3 (土木計画学), 69(5), I_563-I_570.
- Pan, Y., Zheng, R. C., Zhang, J., & Yao, X. (2019). Predicting bike sharing demand using recurrent neural networks. Procedia computer science, 147, 562-566.
- Jiang, W., 2022. Bike sharing usage prediction with deep learning: a survey. Neural Computing and Applications 34, 15369–15385.
- Ma, X., Yin, Y., Jin, Y., He, M., & Zhu, M. (2022). Short-term prediction of bike-sharing demand using multi-source data: a spatial-temporal graph attentional LSTM approach. Applied Sciences, 12(3), 1161.
- Lin, L., He, Z., & Peeta, S. (2018). Predicting station-level hourly demand in a large-scale bike-sharing network: A graph convolutional neural network approach. Transportation Research Part C: Emerging Technologies, 97, 258-276.
- Chen, T., & Guestrin, C. (2016, August). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining (pp. 785-794).
後記
本研究は、MDAトップ人材養成特別演習の一環として、多分野の学生が参加し、指導教員の川島先生、データサイエンティストの塩崎先生(野村総合研究所)、および支援教員の和田先生とオム先生のご指導のもと、つくば市サイクルコミュニティ推進室の中村様、飯田様、柳田様と協力しました。約6か月間にわたり、月2回の全体ミーティングと週1回の学生間グループワークで研究を実施しました。
このチームはつくチャリの赤字問題に取り組みましたが、多くの制御可能な要因が関与するため、当初は焦点を絞るのに苦労しました。さらに、稲葉さんを除き、交通に関する研究経験を持つメンバーがいなかったため、初期段階では学生が現状把握と既存研究の調査・整理を行い、先生方が研究の方向性を導いてくださいました。また、つくば市からも貴重なデータや資料の提供、政策的な要望の共有など、多大なサポートをいただきました。こうした試行錯誤の中、渡邉さんと稲葉さんがいち早く需要モデルの構築に取り組み、分析を開始し、研究方針の確立に大きく貢献しました。その結果、中間発表前に研究の方向性を明確にすることができました。
最終発表までの期間は、各メンバーが希望や専門性に応じてデータ分析を進めました。渡邉さんはポアソン回帰モデルを用いた需要予測、ZHENGさんはGIS分析、稲葉さんはデータ整理を担当し、モデル間のデータ整合性を確保しました。また、Liさんと堤さんは情報学の知識を活かし、AIモデルや最適化手法を活用しました。さらに、(株)NTTデータから提供された人流データが需要モデルの構築において重要な役割を果たし、最終成果へとつながりました。
今回の研究では、実証研究によるモデルの改良や政策実施への直接的な応用には至りませんでしたが、その成果はつくば市の今後のポート新設位置の検討の基礎資料として役立つとの評価をいただけました。最後に、本研究にご協力いただいたすべての方々に、心より感謝申し上げます。