

研究の概要
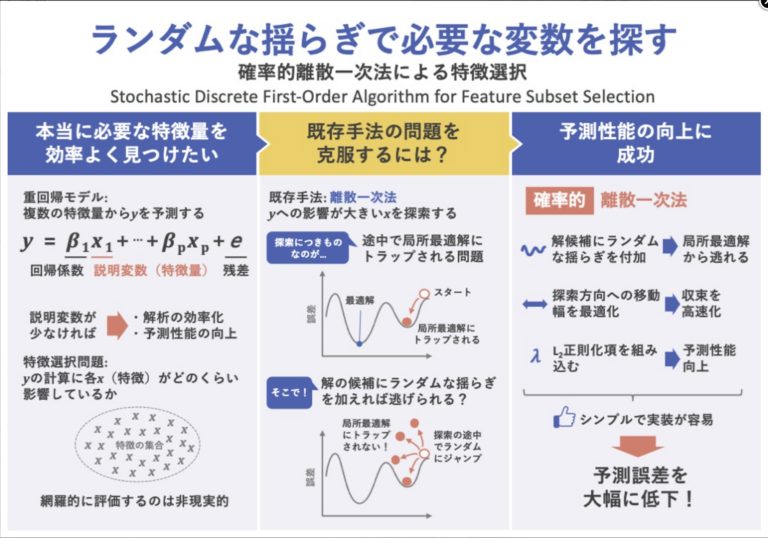
背景と課題
特徴選択(問題)とは、その予測モデルの作成時に有効な特徴量(説明変数)を選択する問題であり、近年では、混合整数最適化の技法を利⽤した特徴選択が注⽬を集めている。
特徴選択により、データ収集・保存コストを削減し、回帰係数の推定をより効率的に行うことができる。また、選択された特徴と回帰モデルによって推論される応答の間の因果関係の解明にも役立つ。さらに、冗長な特徴を排除することで、予測性能を向上させることができる。
特徴の最良の部分集合を見つけるための網羅的な方法は、特徴のすべての可能な部分集合の品質を評価することである。しかし、この方法では、特徴数が少ない場合を除き、計算負荷が大きく、実行不可能である。
多くの先行研究では、大規模な部分集合選択問題を処理するためのヒューリスティック最適化アルゴリズムに焦点を当てている。この種のアルゴリズムで最もよく知られているのはステップワイズ法であり、これは一度に1つの特徴量の追加と削除を繰り返すものである。
近年、スパース推定のために様々な正則化手法が研究されており、中で最も一般的に用いられているのがLassoである。Lassoでは不要な回帰係数を0にするL1正則化項が採用されている。
Bertsimasらは、特徴部分集合選択問題の近似最適解を効率的に見つけるための離散一次(DFO)法を提案している。しかしDFOアルゴリズムは、局所最適解にトラップされてしまうと脱出できない。このため、Bertsimasらは、ランダムな初期化を行い、繰り返してDFOアルゴリズムを実行することを提案している。
本研究では、DFO法の改良版である確率的離散一次法を提案する。これは、局所最適解から逃れるために、解候補にランダムな揺らぎを加えるものである。さらに、高速に収束させるために、勾配降下方向に最適なステップサイズを計算する。また、得られるモデルの予測性能を向上させるために、L2正則化項を組み込む。
提案手法
特徴選択問題を定式化する。サンプル数n、特徴量の個数pの時、応答値のベクトルを𝒚 ∈ ℝn×1、特徴量の値(説明変数)の⾏列を𝑿 ∈ ℝn×p、偏回帰係数のベクトルを𝜷 ∈ ℝp×1とすると、重回帰モデルは、y = X𝜷 + e と表せる。ここで、eは予測誤差を表す。
特徴選択問題は、このeを最小化する一定個数の特徴を見つけるという最適化問題である。すなわち、
minimize𝜷 f(𝜷) := 1/2||y – X𝜷||22 (1)
subject to ||𝜷||0 ≤ k (2)
ここで、||𝜷||0は𝜷の0ではない要素の個数(すなわち特徴量の個数)を、k ( < min {n, p} ) は求める部分集合の大きさを表す。
離散一次法
従来手法である離散一次法は次のように表せる。
- 十分小さな正数として閾値δを決める。||𝜷(1)||0 ≤ kとなる 𝜷(1) ∈ ℝn×1をセット、m ← 1とする。
- 𝜷を更新する。𝜷(m+1) ∈ ℋk(𝜷(m) – 1/L∇f(𝜷(m)))
- もし、|f(β(m)) – f(β(m+1))| ≤ δなら、アルゴリズムは停止し、β(m+1)を解とする。
- m ← m + 1として、ステップ1に戻る。
ここでLは、fの勾配に関するリプシッツ定数である。すなわち、全てのη, β ∈ ℝn×1に対し、||∇f(η) – ∇f(β)||2 ≤ L||η – β||2を満たす。式(1)より、∇f(β) = XTXβ – XTyである。
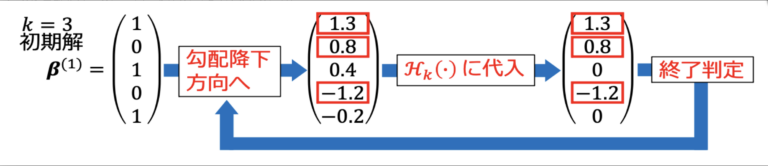
また、ℋkは、絶対値の降順で𝑘 + 1番⽬以降の要素をゼロに変換する作⽤素を表す(図1)。例えば、β = (1.3, 0.8, 0.4, -1.2, -0.2)T、k = 3のとき、ℋk(β)は、βを絶対値の降順に並び替えた(1.3, -1.2, 0.8, 0.4, -0.2)のうちk + 1番目以降を0にした(1.3, -1.2, 0.8, 0, 0)もの、すなわち、ℋk(β) = (1.3, 0.8, 0, -1.2, 0)となる。
確率的離散一次法
提案手法である確率的離散一次法では、従来手法におけるステップ2を、次の通り改良する。
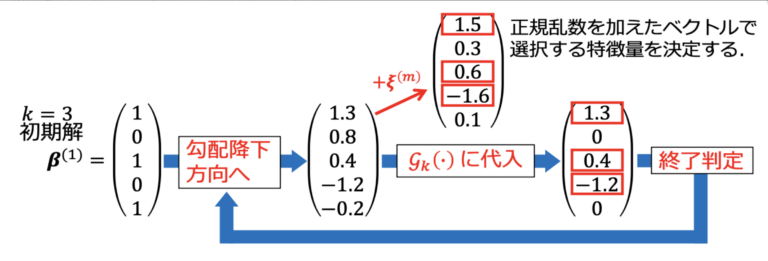
- βを更新する。β(m+1) ∈ Gk(β(m) – 1/L∇f(β(m)) | ξ(m))
ここで、ξ(m) ∈ ℝp×1は平均ゼロ、分散𝜎2mの独⽴な正規乱数から成るベクトルである。Gkはℋkと同じく、絶対値の降順で𝑘 + 1番⽬以降の要素をゼロに変換する作⽤素であるが、絶対値の降順に並び替える際に、正規乱数を加える点が異なる(図2)。この手続きにより、局所最適解から脱出できるようになる。
提案⼿法ではさらに収束速度向上のため、探索⽅向への移動幅を最適化する。また、予測性能向上のため、⽬的関数に𝐿2罰則項を導⼊する。
評価・実証
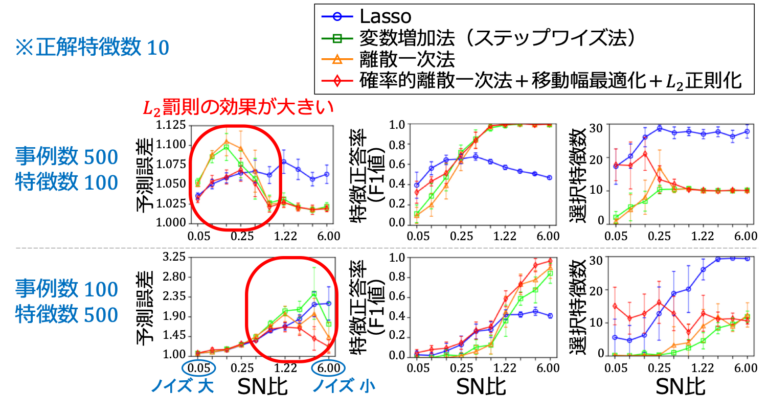
重回帰モデルの実験を行い、提案手法の有効性を検証した。実験データは次のとおりである。
- 偏回帰係数 β* = (1, 𝟎T, 1, 𝟎T,…, 1, 𝟎T)T ∈ ℝp×1
- 特徴量の⾏列𝑿 ∈ ℝn×p(Np (𝟎, 𝚺)の独⽴同分布で⽣成。共分散行列Σの成分(i, j)は0.7|i-j|)
- 応答ベクトル𝒚 ∈ ℝn×1(Nn (𝑿β*, τ2I)で⽣成。)
SN比: 信号対雑音比
τ2=(β)T𝚺β*/SN比
また、評価指標として、予測誤差、特徴正答率(F1値: 正しい特徴量を選択した割合)、選択特徴数を求めた。他の⼿法との予測性能の⽐較を行った(図3)。
成果と提案
本研究では、重回帰モデルの特徴量(説明変数)の部分集合を選択するための確率的離散一次法を提案した。提案手法では、局所最適解から逃れられるように解候補にランダムな揺らぎを加えた。高速な収束のために、勾配降下方向の最適なステップサイズを導出し、予測性能向上を図りL2正則化項を組み込んだ。
シミュレーションの結果、我々の手法は、ランダムな初期化を行った離散一次法を繰り返し実行した場合に比べて、サンプル外予測誤差を大幅に減少させることが確認された。さらに、我々の手法は、部分集合の選択と予測の両方の面で、Lassoや変数増加法(ステップワイズ法)よりも優れた精度を提供した。
これらの結果に加えて、我々の手法が非常にシンプルで理解しやすく、実装が容易であることも注目すべき点である。これらの特性は、研究者や企業のデータアナリストにとって魅力的なものとなるだろう。
この記事は、下記の論文を要約したものです
⼯藤 晃太(2021)確率的離散一次法による一般化線形モデルの特徴選択、2020年度 筑波大学 大学院 博士課程 システム情報工学研究科 修士論文。
後記
- 多くの設定で数値実験を行っており、なかなか良い結果が得られず苦労しました。アルゴリズムの実装などにミスがあるのか、アルゴリズム自体がダメなのかを常に考えながら取り組みました。

アタッチメント
データセット・分析用コード
| No. | 作成者 | タイトル | データ | コード | 参考資料 | 掲載日 | 備考欄 |
| 1 | 工藤晃太 | ランダムな揺らぎで必要な変数を探す | ○ | ○ | ○ | 2021.04.01 | Creative Commons |
| 2 | 岩永健太郎 | これから伸びる研究の芽を探し出す | ○※※※データサイズ大きいためリンク貼れません | ○ | ○ | 2021.04.01 | Creative Commons |
| 3 | 水上印刷株式会社 | 複数モデルの組み合わせによる作業時間予測 | ○ | ○ | ○ | 2021.08.01 | 再配布不可 |